Microphone arrays are powerful listening and recording devices composed of many individual microphones operating together in tandem. Many popular microphone arrays (such as the one found in the Amazon Echo) are arranged circularly, but they can be in any configuration the designer chooses. In our Augmented Listening Lab, we strive to make these arrays wearable to assist the hard of hearing or to serve recording needs. Over the past year, I have been constructing functional prototypes of microphone arrays using MEMS microphones and FPGAs.

Above is a MEMS microphone breakout board created by Adafruit. You can find it here: https://www.adafruit.com/product/3421
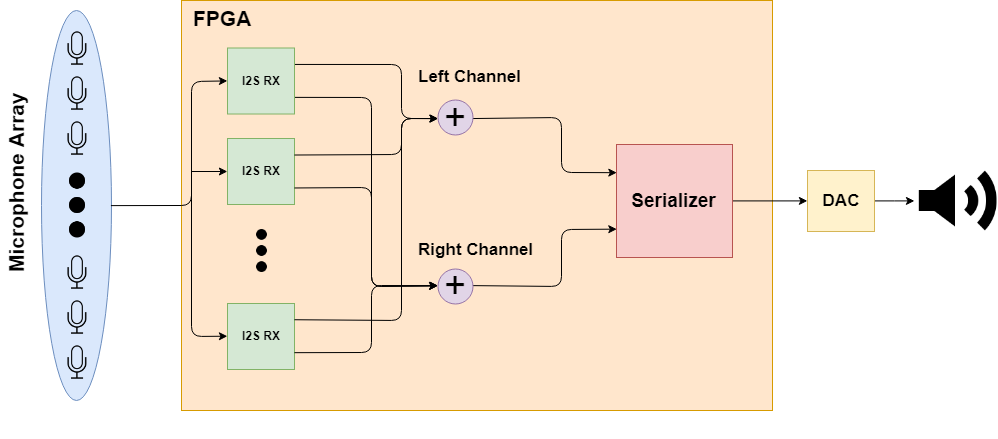
When placing these microphones into an array, they all share the Bit Clock, Left/Right Clock, 3V and Ground signals. All of the microphones share the same clock! Pairs of microphones share one Data Out line that goes to our array processing unit (in our lab we use an FPGA) and the Select pin distinguishes left and right channels for each pair.
The first microphone array I constructed was using a construction helmet! The best microphone arrays leverage spatial area – the larger area the microphones surround or cover, the clearer the audio is. Sometimes in our lab, we test audio using microphone arrays placed on sombreros – a wide and spacious area. Another characteristic of good microphone array design is spacing the microphones evenly around the area. The construction helmet array I built had 12 microphones spaced around the outside on standoffs and I kept the wires on the inside.


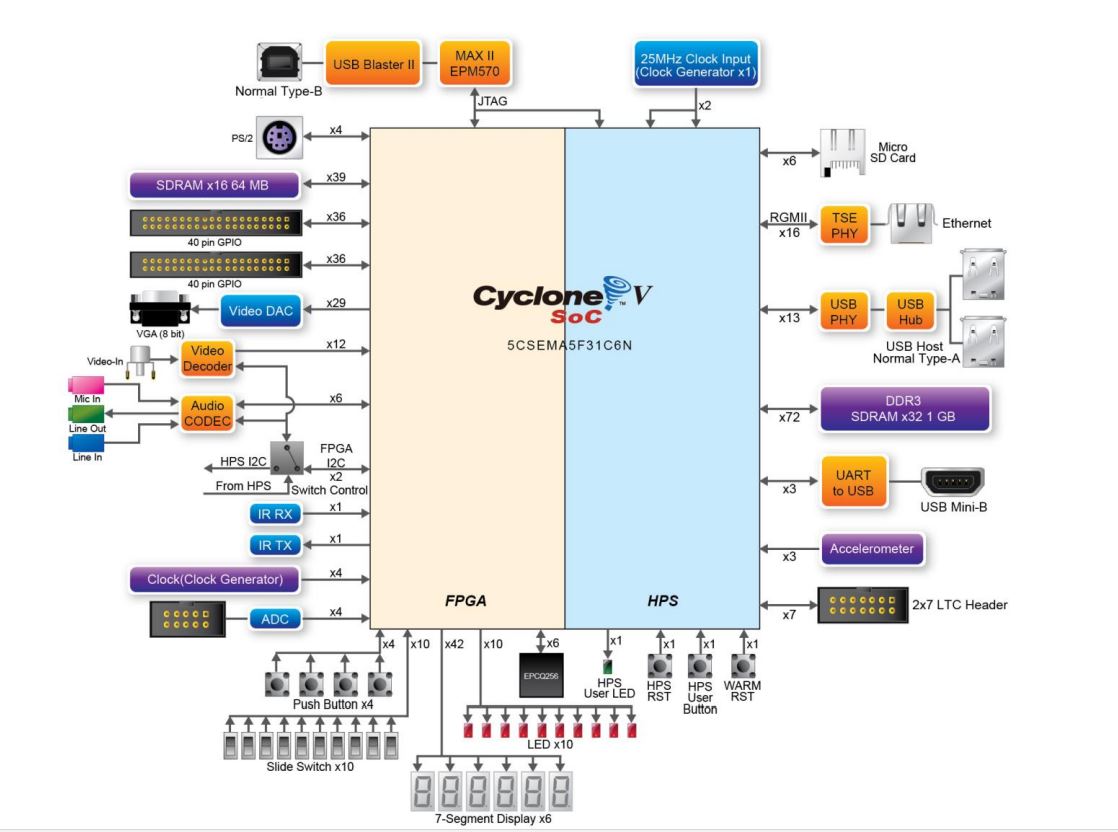
Finally, we use a Field Programmable Gate Array (FPGA) to do real time processing on these microphone arrays. SystemVerilog makes it easy to build modules that control microphone pairs and channels. FPGAs are best used in situations where performance needs to be maximized, in this case we need to reduce latency as much as possible. In SystemVerilog we can build software for our specific application and declare the necessary constraints to make our array as responsive and efficient as possible.
My next goal was to create a microphone array prototype thats wearable and has greater aesthetic appeal than the construction helmet. My colleague, Uriah, designed a pair of black, over-the-ear headphones that contain up to 11 MEMS microphones. The first iteration of this design was breadboarded but future iterations will be cleaned up with a neat PCB design.

A pic of me wearing the breadboarded, over-the-ear headphone array.