This post describes our paper “Adaptive Crosstalk Cancellation and Spatialization for Dynamic Group Conversation Enhancement Using Mobile and Wearable Devices,” presented at the International Workshop on Acoustic Signal Enhancement (IWAENC) in September 2022.
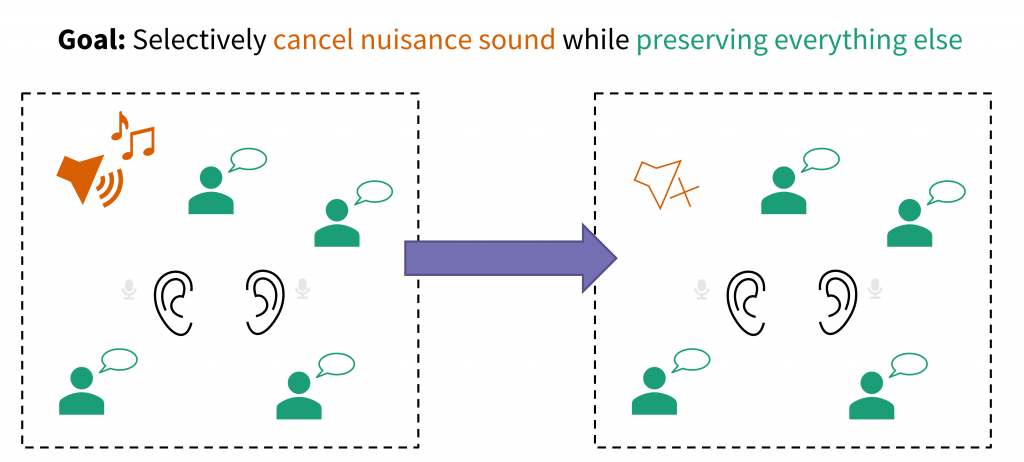
One of the most common complaints from people with hearing loss – and everyone else, really – is that it’s hard to hear in noisy places like restaurants. Group conversations are especially difficult since the listener needs to keep track of multiple people who sometimes interrupt or talk over each other. Conventional hearing aids and other listening devices don’t work well for noisy group conversations. Our team at the Illinois Augmented Listening Laboratory is developing systems to help people hear better in group conversations by connecting hearing devices with other nearby devices. Previously, we showed how wireless remote microphone systems can be improved to support group conversations and how a microphone array can enhance talkers in the group while removing outside noise. But both of those approaches rely on specialized hardware, which isn’t always practical. What if we could build a system using devices that users already have with them?
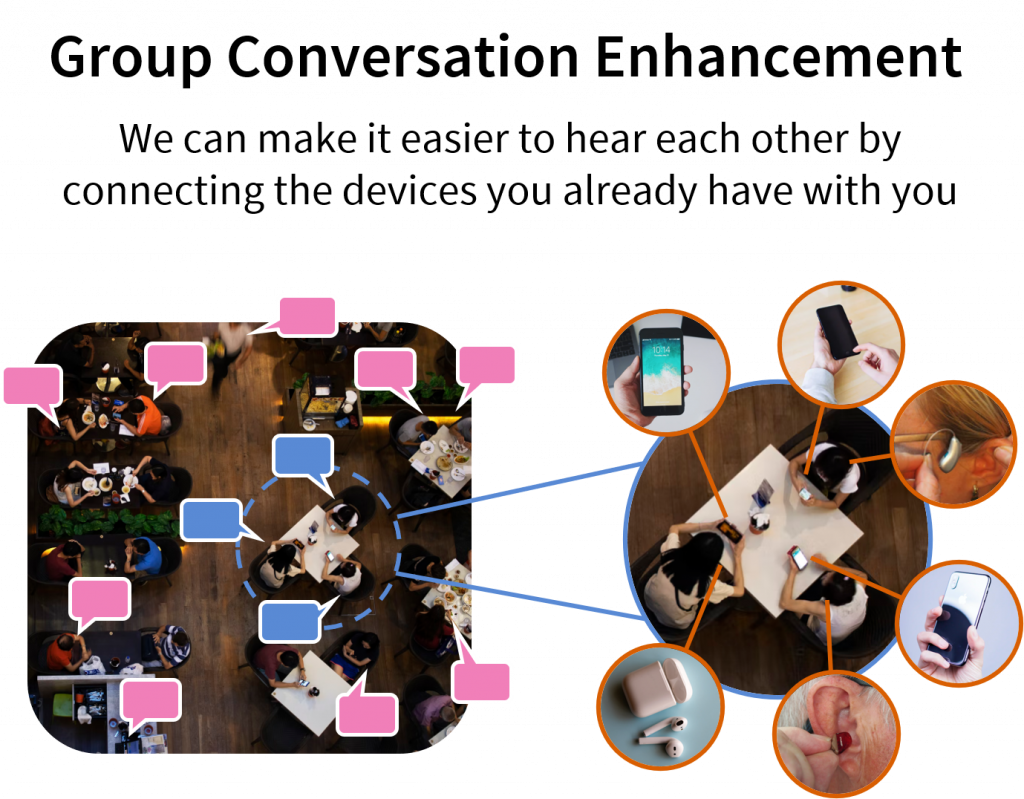
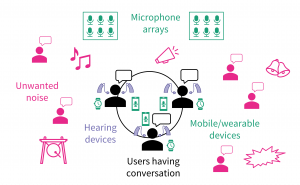
We can connect together hearing devices and smartphones to enhance speech from group members and remove unwanted background noise.
In this work, we enhance a group conversation by connecting together the hearing devices and mobile phones of everyone in the group. Each user wears a pair of earpieces – which could be hearing aids, “hearables”, or wireless earbuds – and places their mobile phone on the table in front of them. The earpieces and phones all transmit audio data to each other, and we use adaptive signal processing to generate an individualized sound mixture for each user. We want each user to be able to hear every other user in the group, but not background noise from other people talking nearby. We also want to remove echoes of the user’s own voice, which can be distracting. And as always, we want to preserve spatial cues that help users tell which direction sound is coming from. Those spatial cues are especially important for group conversations where multiple people might talk at once.