This work was presented at the 184th Meeting of the Acoustical Society of America, May 2023, in Chicago, Illinois.
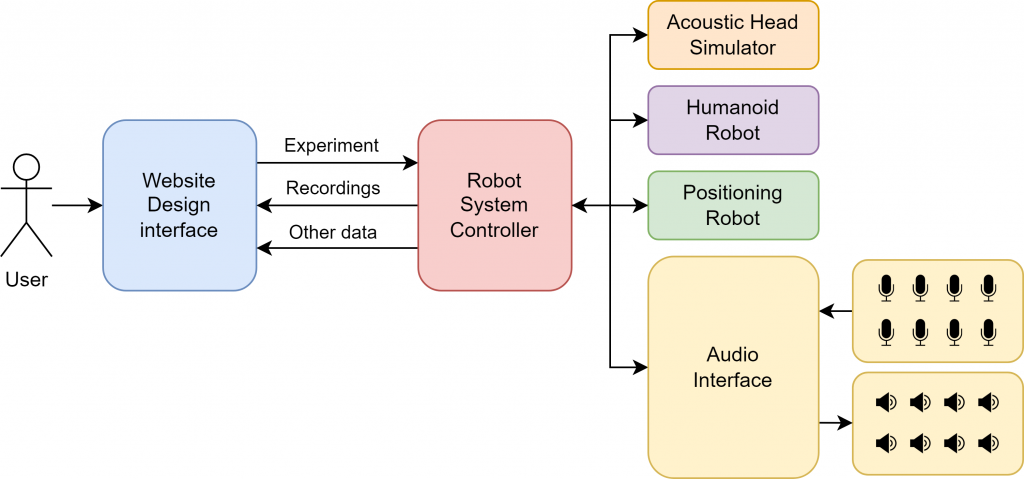
This project is part of the larger Mechatronic Acoustic Research System, a tool for roboticized, automatic audio data collection.
In group conversations, a listener will hear speech coming from many directions of arrival. Human listeners can discern where a particular sound is coming from based on the difference in volume and timing of sound at their left and right ears: these are referred to in the literature as interaural level and time differences.
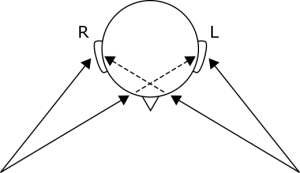
While the brain automatically performs this localization, computers must rely on algorithms. Developing algorithms that are sufficiently accurate, quick, and robust is the work of acoustical signal processing researchers. To do so, researchers need datasets of spatial audio that mimic what is sensed by the ears of a real listener.
Acoustic head simulators provide a solution for generating such datasets. These simulators are designed to have similar absorptive and structural properties as a real human head, and unlike real humans, can be stationed in a lab 24/7 and actuated for precise and repeatable motion.

However, research-grade acoustic head simulators can be prohibitively expensive. To achieve high levels of realism, expensive materials and actuators are used, which raises typical prices into the range of tens of thousands of dollars. As such, very few labs will have access to multiple head simulators, which is necessary for simulating group conversations.
We investigate the application of 3D printing technology to the fabrication of head simulators. In recent years, 3D printing has become a cheap and accessible means of producing highly complicated structures. This makes it uniquely suited to the complex geometry of the human ears and head, both of which significantly affect interaural levels and delay.



To allow for movement of each individual head, we also design a multi-axial turret that the head can lock onto to. This lets the simulators nod and turn, mimicking natural gestures. Researchers can use this feature to evaluate the robustness and responsiveness of their algorithms to spatial perturbations.

By designing a 3D printable, actuated head simulator, we aim to enable anyone to fabricate many such devices for their own research.