ArcGIS StoryMaps is a handy tool for combining narrative, images, and maps to present information in an engaging way. Organizations have used StoryMaps for everything from celebrating their conservation achievements on their 25th anniversary to exploring urban diversity in Prague. The possibilities are vast, which can be both exciting and intimidating for people who are just getting started. I want to share some of my favorite StoryMap examples, which will demonstrate how certain StoryMap tools can be used and hopefully provide inspiration for your project.
A Homecoming for Gonarezhou’s Black Rhinos

If GIS and map creation are a bit outside your wheel-house, no worries! A Homecoming for Gonarezhou’s Black Rhinos is a StoryMap created by the Rhino Recovery Fund that is a great example of how a StoryMap can be made without using any maps. It’s also a good example of the timeline feature as well as making great use of a custom theme by incorporating the nonprofit’s signature pink into the story’s design.
Sounds of the Wild West

Sounds of the Wild West is a StoryMap created by Acoustic Atlas that takes you on an audio tour of four different Montana ecosystems. This StoryMap is a lovely example of how powerful images and audio can immerse people in a location, enhancing their understanding of the information presented. The authors also made great use of the StoryMap sidecar, layering text, images, and audio to create their tour.
California’s Superbloom

Speaking of beautiful photos, this StoryMap about California’s Superbloom is full of them! It’s a great example of the StoryMap image gallery and “swipe” tools. The StoryMap swipe tool allows you to juxtapose different maps or images, revealing the difference between, for example, historical and modern photos, or satellite imagery during different times of year in the same region.
The Surprising State of Africa’s Giraffes
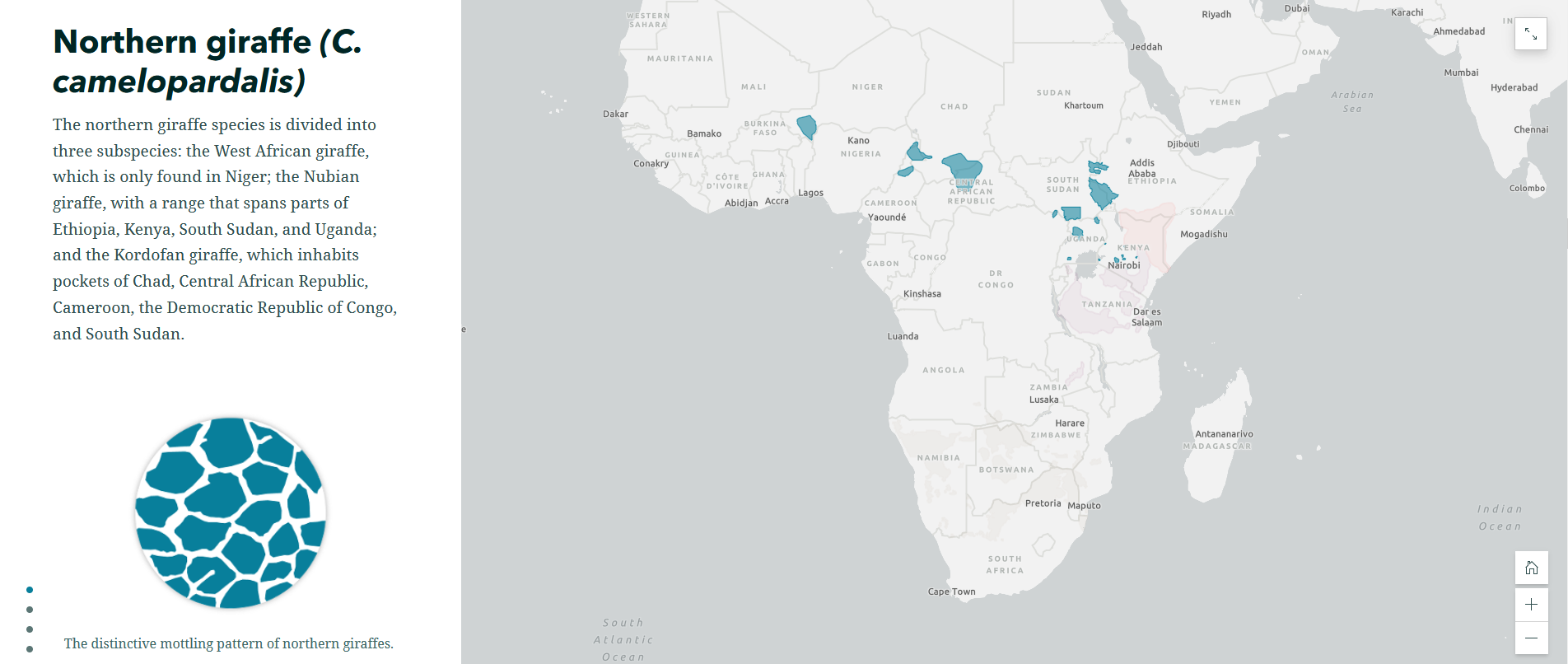
The Surprising State of Africa’s Giraffes is a StoryMap created by ESRI’s StoryMaps team that demonstrates another great use for the sidecar. As users scroll through the sidecar pictured above, different regions of the map are highlighted in an almost animated effect. This not only provides geographic context to the information, but does so in a dynamic way. This StoryMap also includes a great example of an express map, which is an easy way to make an interactive map without any GIS experience or complicated software.
Map Tour Examples
StoryMaps also features a tool that allows you to take users on a tour around the world – or just around your hometown. The map tour comes in two forms: a guided tour, like the one exemplified in Crowded Skies, Expanding Airports; and an explorer tour, such as The Things that Stay with Us.
StoryMaps Gallery
There are so many different forms a StoryMap can take! To see even more possibilities, check out the StoryMaps Gallery to explore nearly a hundred different examples. If you’re ready to get your feet wet but want a bit more support, keep an eye on the Savvy Researcher calendar for upcoming StoryMap workshops at the UIUC Main Library.