
This post describes our new massive distributed microphone array dataset, which is available for download from the Illinois Databank and is featured an upcoming paper at CAMSAP 2019.

The conference room used for the massive distributed array dataset.
Listening in loud noise is hard: we only have two ears, after all, but a crowded party might have dozens or even hundreds of people talking at once. Our ears are hopelessly outnumbered! Augmented listening devices, however, are not limited by physiology: they could use hundreds of microphones spread all across a room to make sense of the jumble of sounds.
Our world is already filled with microphones. There are multiple microphones in every smartphone, laptop, smart speaker, conferencing system, and hearing aid. As microphone technology and wireless networks improve, it will be possible to place hundreds of microphones throughout crowded spaces to help us hear better. Massive-scale distributed arrays are more useful than compact arrays because they are spread around and among the sound sources. One user’s listening device might have trouble distinguishing between two voices on the other side of the room, but wearable microphones on those talkers can provide excellent information about their speech signals.
Many researchers, including our team, are developing algorithms that can harness information from massive-scale arrays, but there is little publicly available data suitable for source separation and audio enhancement research at such a large scale. To facilitate this research, we have released a new dataset with 10 speech sources and 160 microphones in a large, reverberant conference room.
Massive-scale array

The distributed array included 16-microphone wearable microphone arrays (left) and 8-microphone tabletop enclosures (right).
The distributed array contains two device types: wearable arrays and tabletop arrays.
There were four wearable arrays of 16 microphones each, for a total of 64 wearable microphones. Six microphones were placed in behind-the-ear earpieces, which resemble a popular style of hearing aid, two were placed on eyeglasses, and the remaining eight were spread across the shirt. (For more wearable array configurations, see our wearable microphone dataset.)
There were also twelve tabletop arrays, each with 8microphones arranged in a circular pattern, for a total of 96 tabletop microphones. These were mounted in custom enclosures designed to resemble popular smart speakers. The enclosures were designed and assembled by Uriah Jones, Matt Skarha, and Ben Stoehr.
Cocktail party experiment
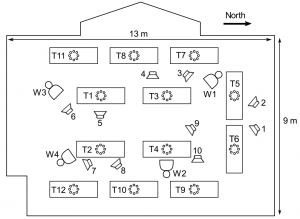
Four wearable arrays, twelve tabletop arrays, and ten loudspeakers were spread throughout the conference room.
The recordings were performed in a large conference room, which is strongly reverberant. Because the sound bounces around the walls so much, it is difficult to tell what direction sound arrives from and to distinguish direct-path signals from later echoes. Source separation researchers still struggle to deal with large, reverberant rooms like this one.
To simulate human talkers, ten loudspeakers were spread throughout the conference room, all facing different directions. Each “talker” faced at least one of the microphone arrays; these nearby arrays provide excellent information about the signals from their neighboring sound sources. The speech signals were derived from the CSTR VCTK Corpus collected by researchers at the University of Edinburgh. Because they were recorded in an anechoic environment, they sound realistic when played back by loudspeakers in a reverberant room.
The dataset contains four types of data for each array device:
- A 55-second recording of the background noise in the room, which is important for designing spatial signal processing systems.
- A 20-second frequency sweep, or chirp, emitted from each of the ten loudspeakers. This can be used to measure acoustic impulse responses, which are the basis of many spatial signal processing algorithms.
- Ten 60-second speech clips, each emitted by one of the loudspeakers. These one-at-a-time recordings provide “clean” signals that can be used to evaluate the results of source separation.
- A 60-second recording of the same speech signals played by all ten loudspeakers simultaneously. This is the signal that our algorithms try to separate.
The measurements were performed by Ryan Corey and Matt Skarha.
The massive distributed microphone array dataset is available now on the Illinois Databank under a Creative Commons Attribution license.