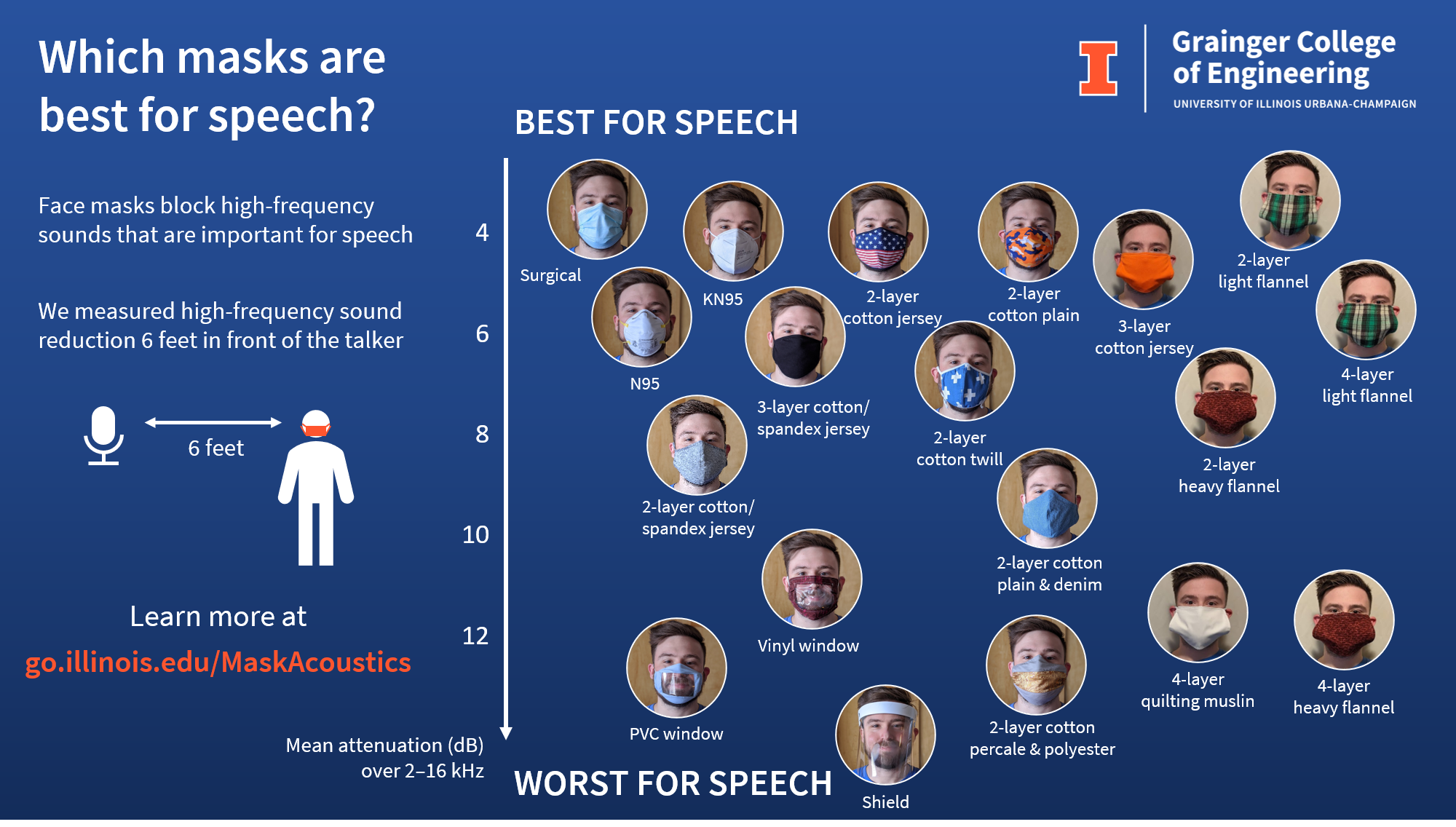
This post describes the results of using simple delay-and-sum beamforming for source separation with the massive distributed microphone array dataset by Ryan Corey, Matt Skarha, and Professor Andrew Singer.
Although source separation (separating distinct and overlapping sound sources from each other and from dispersed noise) in a small, quiet lab with only a few speakers usually produces excellent results, such a situation may not always be present. In a large reverberant room with many speakers, for example, it may be difficult for a person or speech recognition system to keep track of and to comprehend what one particular speaker is saying. But using source separation in such a scenario to improve intelligibility is quite difficult without having external information that in itself may also be difficult to obtain.
Many source separation methods work well up to only a certain number of speakers – typically not much more than four or five. Moreover, some of these methods rely on constraining the number of microphones to an amount equal to the number of sources, and will scale poorly in terms of results, if at all, with the addition of more microphones. Limiting the number of microphones to the number of speakers will not work in these difficult scenarios, but adding more microphones may help, due to the greater amount of spatial information made available by the additional microphones. Therefore, the motivation behind this experiment was to find a suitable source separation method, or series of such methods, that could leverage the “massive” number of microphones used in the Massive Distributed Microphone Array Dataset and solve the particularly challenging problem of separating ten speech sources. Ideally, the algorithm would rely on as little external information as possible, instead relying on the wealth of information gathered by the microphone arrays distributed around the conference room. Thus, the delay-and-sum beamformer was first considered for this task, because it only requires the locations of each source and microphone, and it inherently scales well with a large number of microphones.
The Dataset
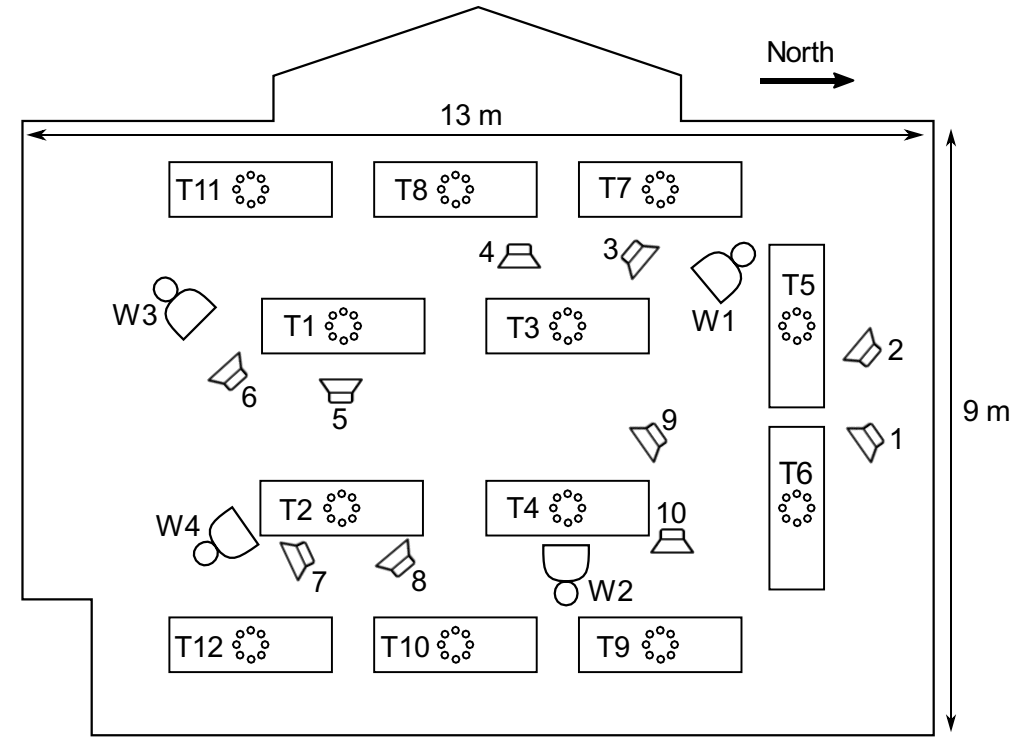
Shown above is a diagram depicting the setup for the Massive Distributed Microphone Array Dataset. Of note is the fact that there are two distinct types of arrays – wearable arrays, denoted by the letter W and numbered from 1-4, and tabletop arrays, denoted by the letter T and numbered from 1-12. Wearable arrays have 16 microphones each, whereas tabletop arrays have 8.