
The project is a close collaboration with Carle Foundation Hospital and focuses on designing a resuscitation support system with integrated workflow, data to decision pipeline, and Medical Device Plug and Play (MDPnP). The main goal is to provide shared and role-based situation awareness in Intensive Care Unit (ICU) to improve the efficiency and safety despite high uncertainty of diagnosis & treatments and difficulties of synchronizing individuals’ actions to workflow. The system will provide a real-time integrated workflow-driven display, facilitating action coordination, timely diagnosis and observation of patient response to the treatments. This will ultimately guide team towards optimal performance while reducing preventable medical errors in ICU often caused by reliance on human memory, verbal communication and notes and disparate displays.
The system under development consists of the major components: data to decision pipeline, workflow manager, and MDPnP manager.
Data to Decision Pipeline consists of three sub-components: context dependent data cleaning, interactive human interface, and risk oriented display.
Context dependent data cleaning: In a medical environment, sensor data can be noisy and misleading. The sensor data interpretation depends on the state of the workflow and the risk embedded in it. For instance, a drop in oxygen saturation value during resuscitation may indicate a malfunction of the ventilator or cardiac output. Alternatively, it may be caused by the subclavian vein catheterization procedure, which may have accidentally punctured the lung.
Interactive Human Interface: Like GPS, our tool assists physicians in navigating through complex data landscapes and always adapts itself to support the physician’s approach. Unlike GPS, the tool likely has a higher error rate. Therefore, an interactive interface will be developed to expose the reasoning behind discovery and allow physicians to input additional relevant context to be incorporated into the machine reasoning.
Risk oriented display provides a prioritized display of information based on the risk to the patient. In addition, the information is grouped according to the corresponding organ system.
Workflow manager drives the user interface to help physicians follow the resuscitation treatment guidelines and prevent safety hazards. In addition, when patient adverse events occur, workflow manager will highlight the current and next steps to be taken.
MDPnP manager manages the physical device, provides abstract sensors and actuators to the upper layers, checks for any inconsistency or conflict in physiological measurements and supervises medical device interactions in order to prevent device-level safety hazards.
For more detailed information, please check the presentation slides
Demo
https://uofi.box.com/s/788tty1m9dpb1r21wwtp
Workflow-centric Verification and Validation
Verification and validation are critical for designing safe and effective cyber-physical medical systems. At design time, the system designs must be formally and fully verified against safety and correctness properties. At run-time, all the performed actions through our system must be validated against known safety hazards. However, unlike traditional verification and validation mechanisms for cyber systems, the medical system cannot lock or rollback the states of physical components, such as patient conditions. Therefore, our system must adapt to the dynamic changes of the physical environment, such as patient conditions. On the other hand, medical workflow intends to capture the best practice to assist medical staff to diagnose and treat patients. In addition, workflow provides the specific context to the cyber system for performing context-dependent verification and validation.
Treatment validation protocol
We developed a validation protocol to assist medical staff to correctly preform treatments, regarding preconditions validation, side effects monitoring, and expected responses checking b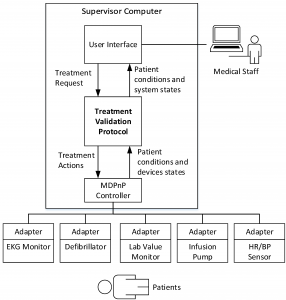 ased on the workflows and pathophysiological models. Specifically, the developed protocol validates treatments by checking preconditions, monitoring potential side effects, and checking patient responses, which can assist medical staff to perform treatments in accordance with medical guidelines. In addition, like model-based feedback control system, the proposed protocol validates the preconditions and corrective treatments and provides feedback to the medical staff.
ased on the workflows and pathophysiological models. Specifically, the developed protocol validates treatments by checking preconditions, monitoring potential side effects, and checking patient responses, which can assist medical staff to perform treatments in accordance with medical guidelines. In addition, like model-based feedback control system, the proposed protocol validates the preconditions and corrective treatments and provides feedback to the medical staff.
Publications:
- Po-Liang Wu, Dhashrath Raguraman, Lui Sha, Richard Berlin, Julian Goldman, 「A Treatment Validation Protocol for Cyber-Physical-Human Medical Systems」. to appear in EUROMICRO Software Engineering and Advanced Application (SEAA) 2014
- Po-Liang Wu, Dhashrath Raguraman, Lui Sha, Richard Berlin, Julian Goldman , 「WiP abstract: A treatment coordination protocol for cyber-physical-human medical systems⌋, Cyber-Physical Systems (ICCPS), 2014 ACM/IEEE International Conference on , vol., no., pp.226,226, 14-17 April 2014
doi: 10.1109/ICCPS.2014.6843739 URL: http://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=6843739&isnumber=6843703
Fault-tolerance
With increase in complexity of the software there is the need for dependable software, and software fault tolerance in particular, arises from the pervasiveness of software, its use in both critical and everyday applications. The means to achieve dependability falls into two major groups: (1) those that are employed during the software
construction process (fault avoidance and fault tolerance), and (2) those that contribute to validation of the software after it is developed (fault removal, fault forecasting and correctness verification). Briefly a one-liner on these techniques :
- Fault avoidance or prevention: to avoid or prevent fault introduction and occurrence
- Fault removal: to detect the existence of faults and eliminate them
- Fault/failure forecasting: to estimate the presence of faults and the occurrence and consequences of failures
- Fault tolerance: to provide service complying with the specification in spite of faults.
Fault tolerance techniques are designed to allow a system to tolerate software faults that remain in the system after its development. They can provide fault tolerance capabilities for single version software environments and multiple version software environments (via design diversity and data diversity). Software fault tolerance techniques provide protection against errors in translating the requirements and algorithms into a programming language, but do not provide explicit protection against errors in specifying the requirements. Software fault tolerance techniques have been used in the aerospace, nuclear power, healthcare, telecommunications and ground transportation industries, among others.
Forward v.s Backward Recovery
When an error occurs in a program, the program generally enters a contaminated or erroneous state. Recovery techniques attempt to return the system to a correct or error-free state. Backward recovery attempts to do this by restoring or rolling back the
system to a previously saved state. It is usually assumed that the previously saved state occurred before the fault manifested itself, that is, that the prior state is error-free. If it is not error-free, the same error may cause problems in the recovery attempt. System states are saved at predetermined recovery points. Recording or saving this previous state is called checkpointing. The state should be checkpointed on stable storage t hat will not be affected by failure. In addition to, and sometimes instead of, checkpointing, incremental checkpointing, audit trail, or logs may be used. Upon error detection, the system state is restored to the last saved state, and operations continue or restart from that state. If the failure occurred after the checkpoint was established, the checkpointed state will be error-free and after the rollback, the system state will
also be error-free.
Forward recovery attempts to do this by finding a new state from which the system can continue operation. This state may be a degraded mode of the previous error-free state. As an alternative to this state transitioning for recovery, forward recovery can utilize error compensation. Error compensation is based on an algorithm that uses redundancy (typically built into the system) to select or derive the correct answer or an acceptable answer. Note that redundant (diverse) software processes are executed in parallel. The redundancy provides a set of potential results or answers from which a fault detection and handling unit performs error compensation and selects or derives an answer deemed correct or acceptable. Most medical actions are real-time and their effect should be assumed to be non reversible in worst case. Hence the backward recovery process is not only time consuming but is also non favorable. Hence we go with the approach of forward recovery where in we resume from the point we left of.
One of the core principles of a resuscitation system and its backup is to have equivalent behavior. Hence we enter into a notion of sequential consistency and hence I would like to introduce some concepts of atomicity. The activity of a group of components constitutes an atomic action if no information flows between that group and the rest of the system for the duration of the activity. An atomic action is an action that is Indivisible, Serializable and Recoverable. The property of atomicity guarantees that if an action successfully executes, its results and the changes it made on shared data become visible for subsequent actions. On the other hand, if a failure occurs inside of an action, the failure is detected and the action returns without changes on shared data. This enables easy damage containment and error handling, since the fault, err propagation, and error recovery all occur within a single atomic action. Therefore, the fault and associated recovery activities will not affect other system activities. If the activity of a system can be decomposed into atomic actions, fault tolerance measures can be constructed for each of the atomic actions independently. Maintaining atomicity is essential in verification as well as recovering via the secondary system.
easy damage containment and error handling, since the fault, err propagation, and error recovery all occur within a single atomic action. Therefore, the fault and associated recovery activities will not affect other system activities. If the activity of a system can be decomposed into atomic actions, fault tolerance measures can be constructed for each of the atomic actions independently. Maintaining atomicity is essential in verification as well as recovering via the secondary system.
Device Configuration Modeling
We shall investigate device configuration models that abstract the dynamics of the ECPH environment. The focus of this investigation is to facilitate verifying the interoperability of medical devices and computing their effect on the interpretation of available measurements in an emergency operation. The work will develop device and measurement models as the building blocks of a configuration model. The configuration modelis then composed from a measurement model and a device model. Efficient analysis of configurations is critical since there may exist a combinatory explosion of possible configurations. One should note that configuration correctness is a context-sensitive issue. An abstraction of crucial aspects of the workflow, such as patient diagnosis, current procedure, and team members’ capabilities must be transmitted to the configuration manager in order to reason about configuration correctness. In a situation-aware reconfiguration, the process of configuration verification will be adaptive to changes in the diagnosis, treatment plan, and the surrounding physical environment.
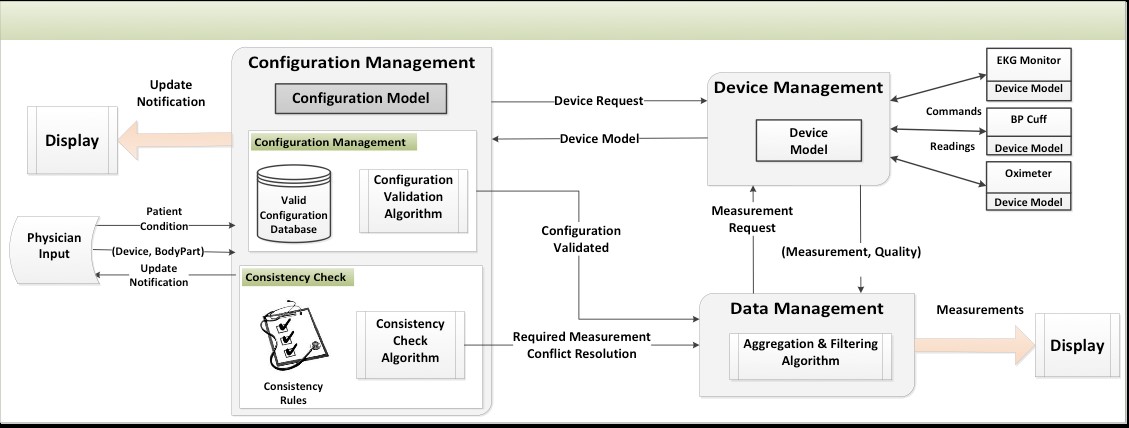
The above figure shows our preliminary architecture design of a configuration management component. Our preliminary results are part of the recent NIH (National Institute of Health) sponsored investigation on safe medical system reconfiguration and interoperability (a.k.a., MDPnP or Medical Device Plug-and-Play). In this project, the focus will be on integrating the configuration manager into the proposed emergency operation support system and modeling and analyzing the necessary interaction between this component and other subsystems.
More specifically, to offer configuration management as an integral part of the emergency operation support system, we shall extend our preliminary results on device configuration modeling and architecture design. First, in order to enable reasoning techniques about configuration correctness, we plan to develop the model for each individual device. The developed device models provide rigorous abstractions in terms of temporal logic for assumptions and guarantees. The runtime verification framework can iteratively and effectively analyze the specifications instead of the detailed device behavior against the current environment. In this manner, the complexity of reconfiguration safety checks is significantly reduced and run-time verification becomes applicable.