Imagine having a sound mixing board for real life: You could turn up the voice of a conversation partner, silence the drone of an airplane engine, or remove echoes from the public address system in a train station. I study augmented listening technologies, like hearing aids and augmented reality systems, that change the way humans experience sound. Using advanced sensing and processing systems, not only can we make listening easier for people with hearing loss, we can also give everyone superhuman hearing.
There are two key challenges in designing augmented listening systems:
- Build technological systems that can hear better than our unaided ears, for example by using dozens or hundreds of microphones spread around a room.
- Process that superhuman sound information into a form that’s useful for humans. For example, we can make it sound like we’re hearing everything using our own ears, but with some sounds turned up and other sounds turned down.
Within those broad challenges, there are numerous technical problems for researchers to solve. This page describes some of the research problems I’ve been working on.
COVID-19 Projects
Face Mask Acoustics
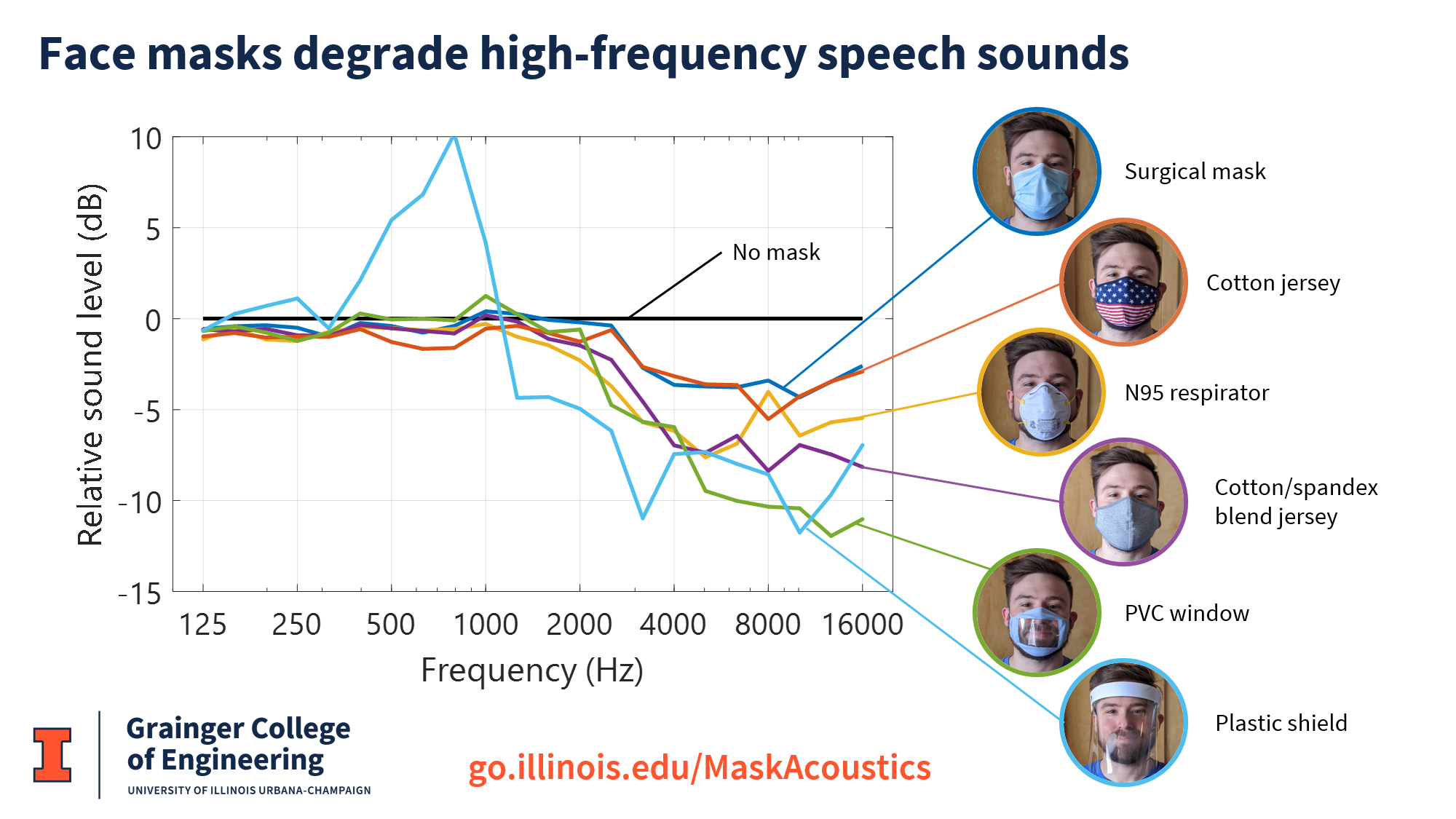 The COVID-19 pandemic introduced new communication barriers, especially for people with hearing loss. Face masks muffle speech and block visual cues, making it harder to understand people. I studied the acoustic effects of various face coverings, including medical, cloth, and transparent masks, and the benefits of using microphones.
The COVID-19 pandemic introduced new communication barriers, especially for people with hearing loss. Face masks muffle speech and block visual cues, making it harder to understand people. I studied the acoustic effects of various face coverings, including medical, cloth, and transparent masks, and the benefits of using microphones.
Ventilator Alarm
 In April 2020, amid widespread fears of a ventilator shortage, a team from the Grainger College of Engineering developed a low-cost, rapidly producible emergency ventilator called the Illinois RapidVent. Our research team helped build a sensor and alarm system that would notify clinicians if patients stopped breathing normally. I adapted an algorithm normally used in hearing aids to track the breathing cycle and detect anomalies. The Illinois RapidAlarm is available as an open-source hardware and software design.
In April 2020, amid widespread fears of a ventilator shortage, a team from the Grainger College of Engineering developed a low-cost, rapidly producible emergency ventilator called the Illinois RapidVent. Our research team helped build a sensor and alarm system that would notify clinicians if patients stopped breathing normally. I adapted an algorithm normally used in hearing aids to track the breathing cycle and detect anomalies. The Illinois RapidAlarm is available as an open-source hardware and software design.
Signal Processing for Assistive Listening
There are a few signal processing systems and algorithms that are specifically developed for listening technology and received little attention from the broader signal processing research community.
Wireless listening systems
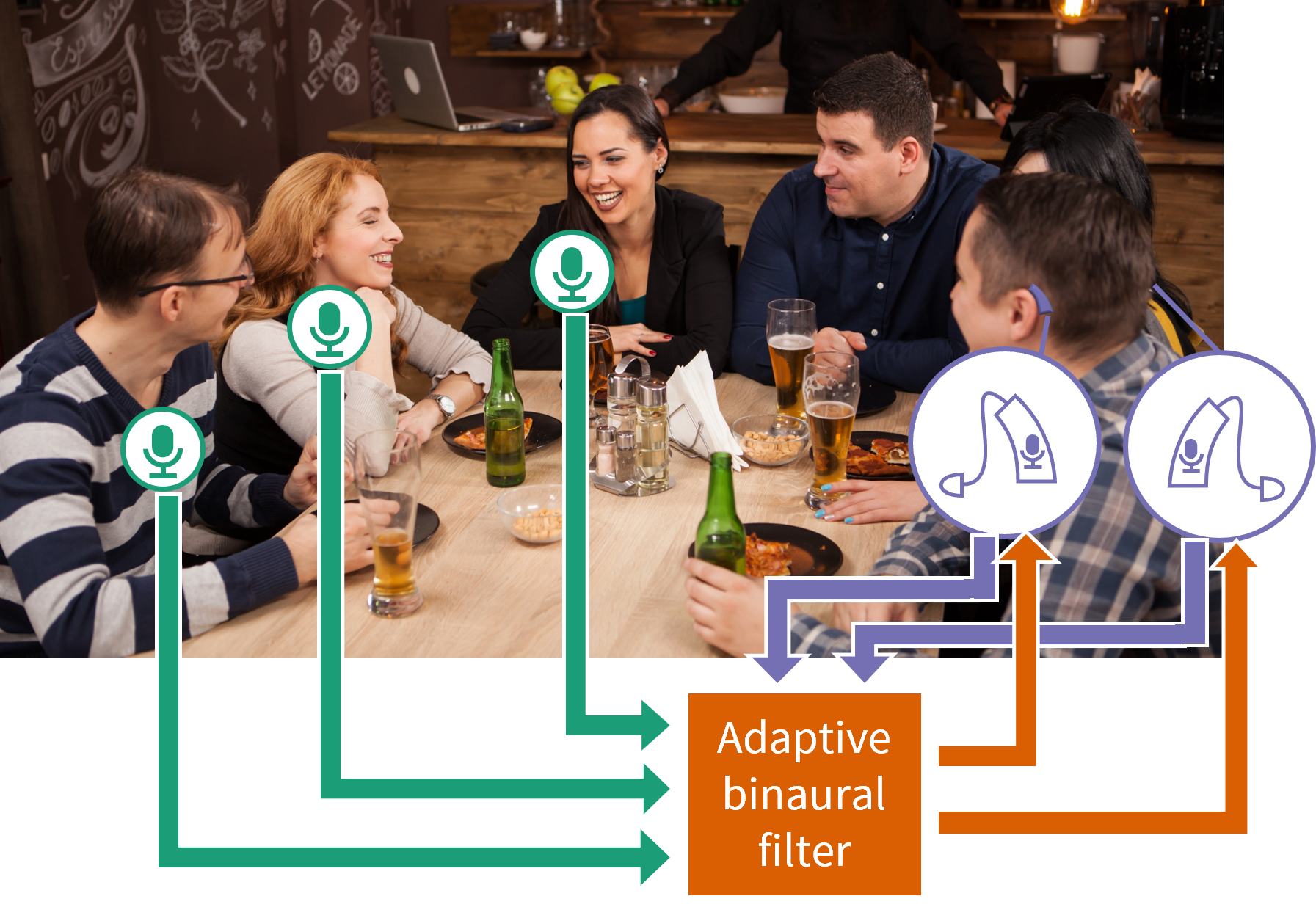 The most reliable way to improve speech intelligibility is to transmit sound directly from a talker to a listener. Most hearing aids come with wireless microphone accessories that can be clipped to a talker, and public venues like theaters broadcast signals from their sound systems. I am developing algorithms to make wireless listening systems more immersive, which is especially helpful for group conversations.
The most reliable way to improve speech intelligibility is to transmit sound directly from a talker to a listener. Most hearing aids come with wireless microphone accessories that can be clipped to a talker, and public venues like theaters broadcast signals from their sound systems. I am developing algorithms to make wireless listening systems more immersive, which is especially helpful for group conversations.
Dynamic range compression
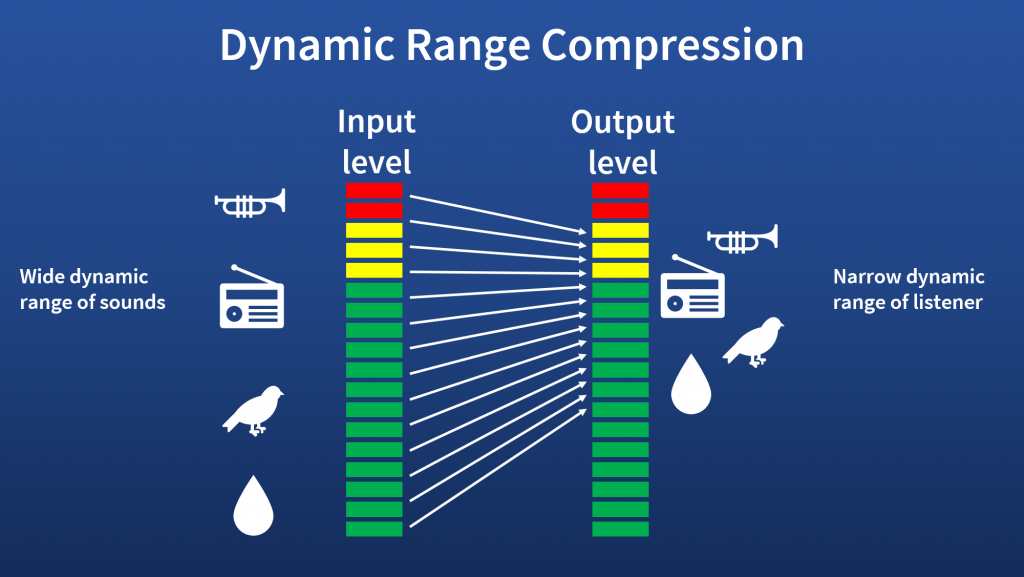 Nearly all hearing aids use an algorithm called dynamic range compression, which makes quiet sounds louder and loud sounds quieter. Compression is important for listening comfort, but it can also cause distortion effects in noisy environments. I am using mathematical models to better understand those distortion effects and design new compression strategies systems for noisy environments.
Nearly all hearing aids use an algorithm called dynamic range compression, which makes quiet sounds louder and loud sounds quieter. Compression is important for listening comfort, but it can also cause distortion effects in noisy environments. I am using mathematical models to better understand those distortion effects and design new compression strategies systems for noisy environments.
Spatial Signal Processing for Human Listeners

To achieve superhuman hearing, our technology needs more information than the unaided ears. We can use microphone arrays, or groups of microphones spread apart from each other in space, to boost sounds coming from certain directions and suppress sounds from other directions. Microphone arrays are widely used in voice-activated smart-home devices, conferencing systems, and laptops, but there are special challenges we face when using them with human listeners:
- We need to process the signals in real time, with only a few milliseconds of delay, or the listener will notice annoying distortion or echoes, especially when hearing their own voice. Most communication and AI applications can tolerate tens or hundreds of milliseconds of delay.
- To help our brain interpret the sounds, we need to make it sound like we’re hearing through our own ears. We must process the sound captured by the microphone array to match the acoustics of the room and the differences in loudness and timing between the left and right ears.
- Unlike a smart speaker on a table or a conferencing system on a wall, humans are constantly moving. We need to design spatial sound processing algorithms that can tolerate motion, and we need to continuously adapt the output to match changing room acoustics and spatial cues.
Wearable Microphone Arrays

Larger microphone arrays have better spatial resolution, meaning they can locate and isolate sounds more precisely. Traditional hearing aids only use one or two microphones per earpiece, so they have a hard time separating sounds from different directions. To build powerful augmented listening systems, we need more microphones spread across a larger area. The team in the Augmented Listening Laboratory has been designing and testing large wearable microphone arrays, with sensors spread across the body and accessories like glasses and hats.
- In 2019, we released an open data set of wearable microphone measurements that researchers can use to study different wearable array designs. The most effective arrays spread microphones around the body, especially the torso, so that each microphones picks up very different sound.
- Our undergraduate research students have been developing functional prototypes using tiny digital MEMS microphones and a field-programmable gate array (FPGA). Unlike a microcontroller or single-board computer, the FPGA can scale to process dozens of microphones in real time.
- Processing data from wearable microphone arrays is more challenging than processing data from fixed array devices because humans constantly move. When microphones are spread across the body, their relative positions can change, making it harder to tell what direction a sound is coming from. I explored the challenges of “deformable” microphone arrays in an award-winning conference paper at WASPAA 2019.
Cooperative Listening Systems

Large wearable microphone arrays have much better spatial diversity than conventional hearing aids, but for truly superhuman listening ability in the most difficult environments, we need microphones spread all over a space. Fortunately, we are already surrounded by network-connected microphones. We can build room-scale microphone arrays by connecting mobile devices, wearables, smart-home devices, infrastructures, and other sensing devices. To make a distributed sensor network useful, we need to address several technical challenges:
- We usually don’t know where the devices are, especially if they are wearables or mobile devices, and they move relative to each other over time.
- Each device has its own analog-to-digital converter, and different devices might sample at slightly different rates. That is not a problem for most applications, but offsets as small as a few parts per million can be harmful for array processing.
- The network will have limited bandwidth and may have too much latency for real-time listening.
I have proposed cooperative processing algorithms that share useful information between devices even if delay, synchronization, or motion make it impossible to use conventional array processing. Our team demonstrated a cooperative listening system with an array of 160 microphones and a set of 10 simultaneous talkers in a large, reverberant room. We published the acoustic measurements and speech recordings in a massive microphone array data set.