Vehicle Detection and Speed Estimation
Keywords: Gaussian mixture model, Logistic regression, Maximum a posterior estimation, Finite state machine, Robust linear regression, RANSAC, Kernel density segmentation, DBSCAN, Hough line detection, Computer vision, Convex Hull, Hough circle detection
Source Code (under development): https://github.com/Lab-Work/Traffic_Sensors_Algorithms
Currently, I am working on a wireless sensor network project which aims to detect vehicles and estimate vehicle speeds using passive infrared cameras and ultrasonic sensors. The following video shows the preliminary results.
Two versions of algorithms have been developed:
- The previous supervised algorithm used GMM and Logistic regression to train a classifier to distinguish vehicles from the background. Then a linear regression model was trained to estimate the speed using the time shifts of peaks from the time series from different pixels. This approach requires labeled training data which is not realistic to collect during the deployment of sensors.
- The current unsupervised algorithm uses a new robust linear regression algorithm which uses kernel density segmentation to separate vehicles.
Recall each vehicle signal can be processed to an approximately linear heat trace (top right figure in the above video), the speed estimation problem is simplified to fit a linear line to such traces. However, there are several challenges:
- Outliers. After background subtraction, there are still outliers in the heat traces frame. So simple linear regression will fail.
- Unknown number of vehicles in frame. So clustering algorithms that require known number of clusters (e.g., k-mean) are not suitable.
- Different widths of traces. So common robust linear regression that uses a fixed width parameter (e.g., RANSAC) do not perform well.
- Overlapping vehicle traces. Common robust linear regression fails to separate vehicles.
The following figures show two cases (varying widths, and overlapping traces).
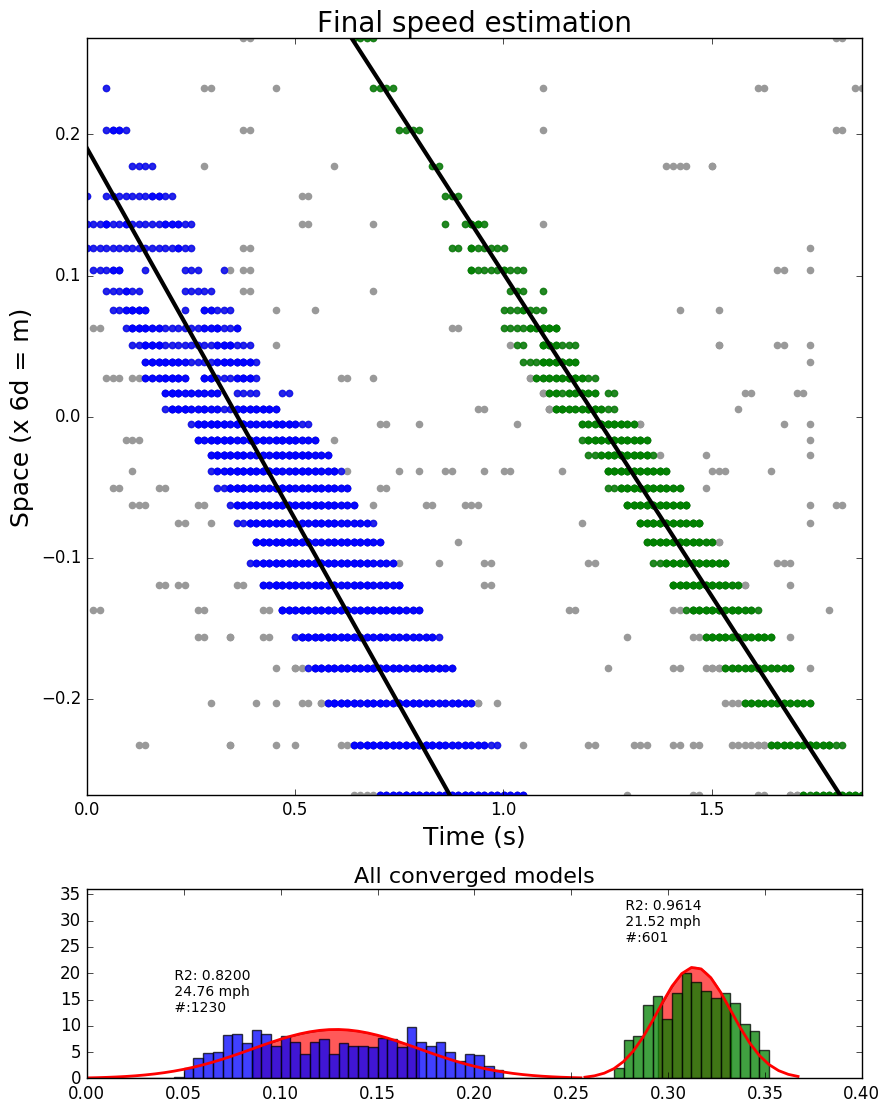
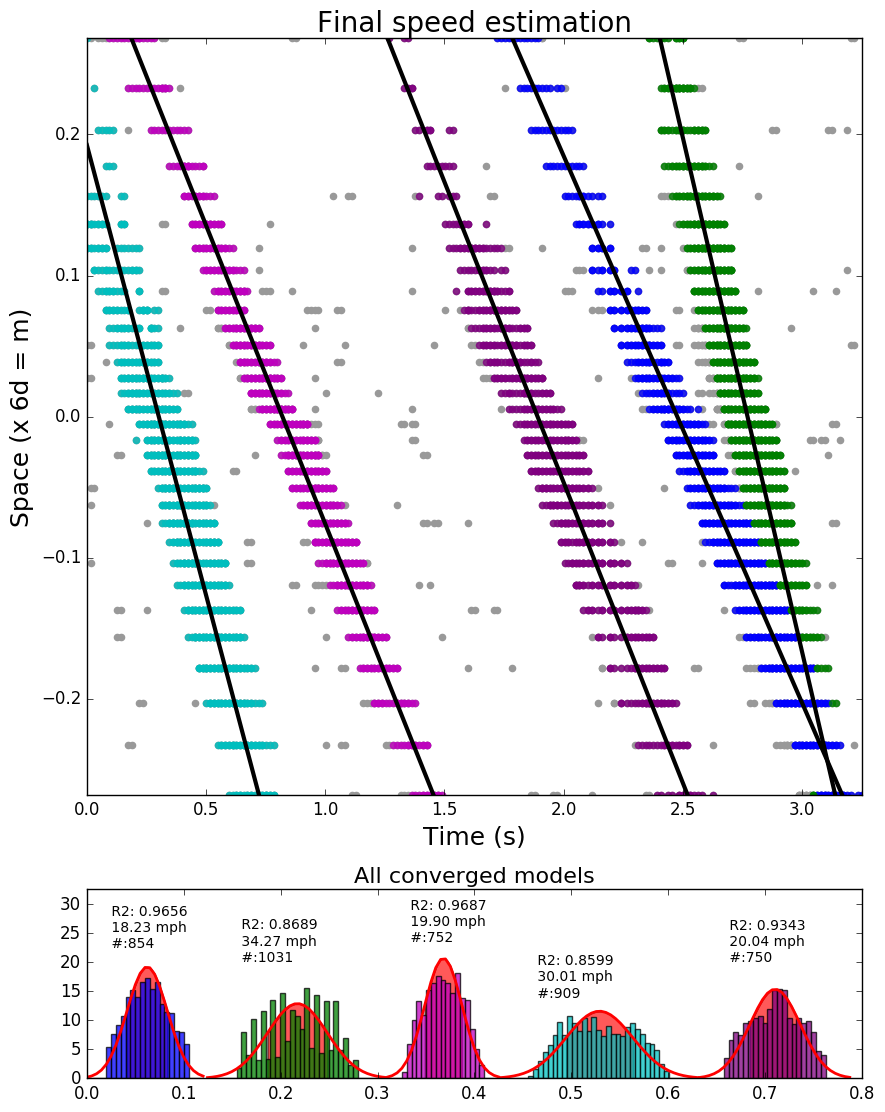
Left: two vehicles with different signal strength. Right: five vehicles where the traces from two vehicles from two lanes overlap.
In both scenarios, the proposed algorithm is capable of correctly identify vehicles and estimate their speeds.
The proposed unsupervised algorithm:
- Background subtraction. Learn a Gaussian distribution model for the background noise and then use MAP to consistently update the distribution parameters. Then use a FSM to extract the vehicle traces.
- Use an iterative robust linear regression with adaptive width parameter to fit a line to the vehicle traces. Unlike RANSAC where each iteration fits a model from a random subsets of all points, the iterative robust linear regression fit a new model to all inliers updated in the previous iteration. This significantly improved the convergence rate (converges in average less than 5 iterations). The width parameter is critical for the fast convergence and good performance: i) in case of bad fitting in the current iteration, the width increases to capture more data points as inliers which improves the fitting in the next iteration; ii) in case of good fitting in the current iteration, the width decreases to remove the outliers in the current model, which refines the line fitting in the next iteration.
- In case of overlapping traces, project the 2D data to 1D by computing the distance of all points to a line, and then perform kernel density segmentation to separate vehicles.
Trip Prediction for the Divvy Bike Sharing Program
Keywords: Bike-sharing, Clustering, LR-ARX predictive models
Background: Divvy is a bike-sharing system in Chicago. Users can take bikes from any station and drop off at any other station. The problems are: i) some stations frequently run out of bikes; ii) other stations frequently become full leaving no space for parking.
The goal of the project is to predict the number of bikes at each station in the near future. The intuition is the trips are highly periodic which allows us to train machine learning models using historical data. The following video is a visualization of the trips occurred in Chicago.
In this project, over 750,000 trips during June~December 2013 were used to identify the periodically patterns and train models for predicting the in and out trips at each station. Overall, simple techniques can be used to predict the in and out trips with a relatively high accuracy. However, due to the small number of bikes at each state, small prediction errors in the in and out trips at each station can accumulate and result in large error of the prediction of the number of bikes at the station. More details can be found here.
Differential Privacy in Traffic Data
Keywords: Differential privacy, Stochastic functions, Laplace distribution, Traffic data analysis
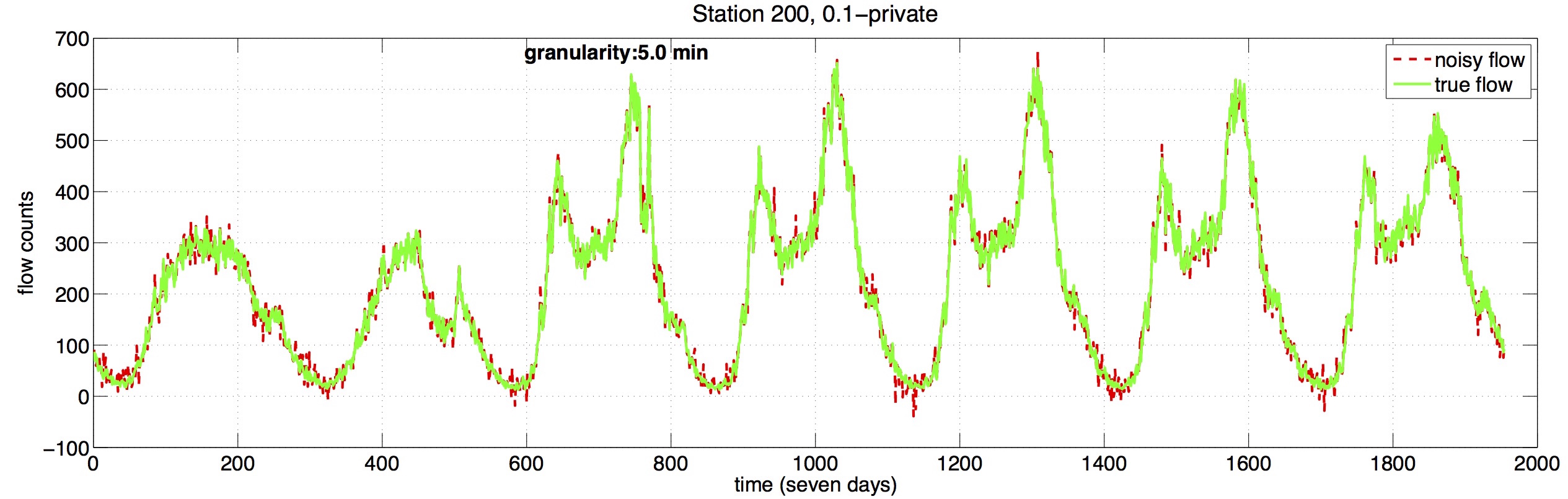
As more and more traffic data being collected, the privacy of travelers is increasingly likely to be compromised. Differential privacy is a theoretical framework which preserves the privacy of travelers while maintaining the valuable information in the dataset. One standard mechanism is to inject noise to the collected true data.
This project is one of the first a few attempts to introduce the differential privacy framework to traffic data. After processing 7 days traffic flow data collected by PeMS in California with over 20 million entries, it was found the traveler’s privacy can be preserved at a sacrifice of slightly increased error (approximately the same level of the measurement error). The result is illustrated in the following figure where the noisy traffic flow data is fairly close to the true traffic flow data while preserving the traveler’s privacy.