
ASIMOV (short for “Algorithm of Selectivity by Incentive and Motivation for Optimized Valuation”) is an agent-based simulation of decision-making processes. It provides a fundamental framework for developing artificial animal behavior and cognition through step-wise modifications, where pre-existing circuitry is plausibly modified for changing function and tested, as in natural evolutionary exaptation. ASIMOV contains a cognitive architecture that is based on the behaviors and neuronal circuitry of the simple predatory sea slug Pleurobranchaea californica, and has since been expanded to include more complex behaviors, such as simple aesthetics and addiction dynamics (Gribkova et al., 2020), episodic memory, and spatial navigation. Code for ASIMOV is available at: https://github.com/Entience/ASIMOV.
Origin in Cyberslug
ASIMOV was built on an earlier simulation, Cyberslug (Brown et al., 2018), itself based on neuronal circuitry of cost-benefit decision of the predatory sea-slug Pleurobranchaea californica. In Cyberslug, a forager affectively integrates sensation, motivation (hunger), and learning to make cost-benefit decisions for approach or avoidance of prey.
Reward Experience in ASIMOV
ASIMOV builds on this with the explicit implementation of reward experience, pain, and homeostatic plasticity to provide realistic valuation of stimuli, and demonstrates how the nature and course of the addiction process emerges as an extreme expression of aesthetic preference. Here is a marvelous illustration of ASIMOV by Rebecca Purchase with a summary by Jared Adelman (Science in Pictures). Be sure to check out and support their amazing work!

Figure 1. ASIMOV’s neural network of foraging decision. The core of this model is the integration of several different elements (Incentive, Satiation, Reward Experience from HRC, and Pain) in the feeding network (Appetitive State), which determines the final approach/avoidance decision and motor output.

Figure 2. ASIMOV FAM simulations, going from sequence memorization (A) to simple cognitive mapping (B) in spatial navigation, where the addition of path integration allows learning and traversal of a map of non-overlapping, unique landmarks, and is the basis for cognitive mapping.
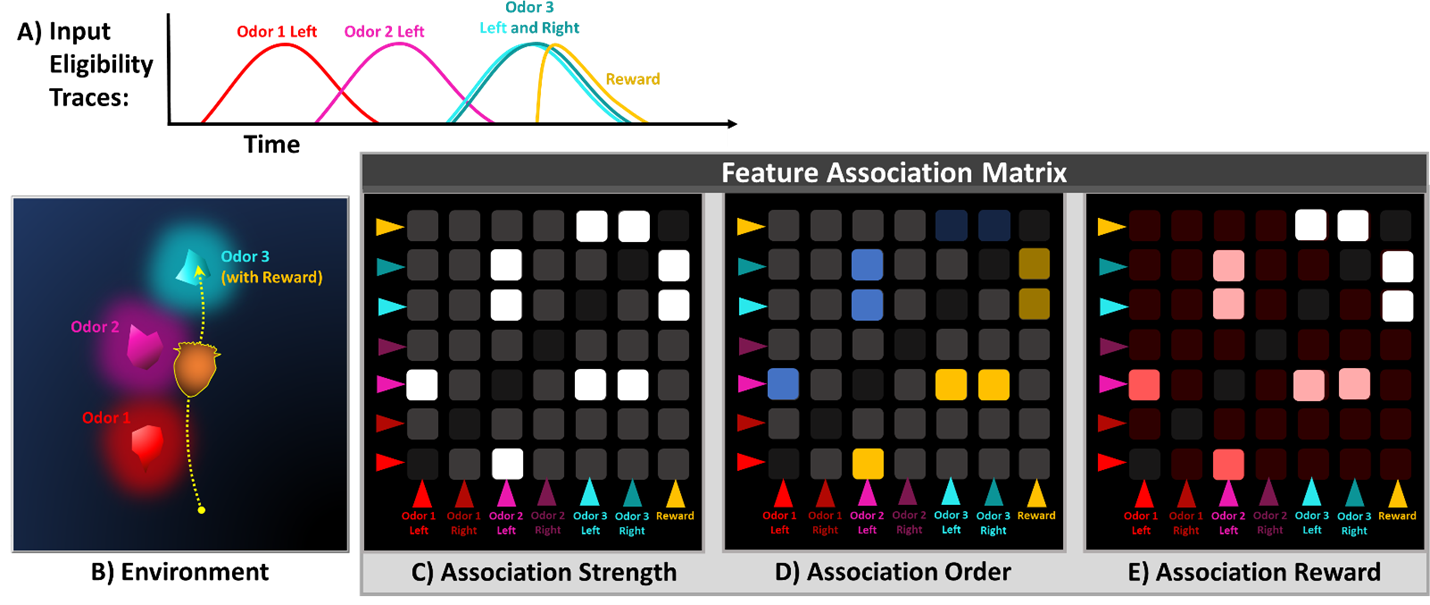
Figure 3. The Feature Association Matrix (FAM) memorizes sequences of odor and reward stimuli (A,B) by chaining learned pair-wise associations. As the agent traverses the sequence of stimuli, it learns the Strength (C) and Order (D) values for each association. When the agent encounters reward at the end of this sequence, reward values (E) are assigned along the established chain, determining sequence salience. Encoding of additional contexts, such as distance and direction information, in each pair-wise association, allows the chain-like construction of more complex spatial and cognitive maps.
A demonstration of ASIMOV’s agent with FAM learning spatial maps:
Brown JW, Caetano-Anollés D, Catanho M, Gribkova E, Ryckman N, Tian K, Voloshin M, Gillette R (2018) Implementing goal-directed foraging decisions of a simpler nervous system in simulation. eNeuro, 5(1). DOI: https://doi.org/10.1523/ENEURO.0400-17.2018.
Gribkova ED, Catanho M, Gillette R (2020) Simple aesthetic sense and addiction emerge in neural relations of cost-benefit decision in foraging. Scientific Reports, 10(1), 11-1. DOI: https://doi.org/10.1038/s41598-020-66465-0