Home
This project targets distributed stream processing systems, which are relatively easy to deploy, manage, and optimize on cloud platforms. A typical distributed stream processing system follows the basic framework shown in Fig. 1. On the input side of the system, new data items, which we will call tuples, continuously arrive at the system for processing. Each tuple has two attributes: its content and timestamp. The timestamp attribute records the exact generation time of the tuple, while the content attribute contains the detailed information associated with the tuple. On the output side of the system, analytics results are flushed to the user. Depending on the particular analytics task, different types of visualization techniques are used to present the analytics results to humans.
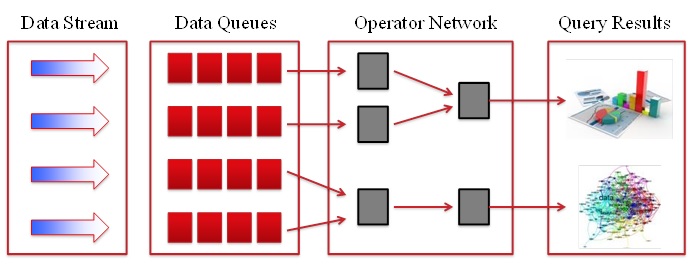
Fig. 1: Model of Real-Time Streaming Analytics Systems
Surveillance video analysis is a good example of the kind of stream processing we target. On the input side, each video frame forwarded to the system is represented by a tuple with a time and image information. The stream processing system runs analytics jobs on the cloud’s distributed computation resources and returns analytics results to the user, such as an analysis of the likelihood of a fight occurring, the degree of potential danger posed by a hiker approaching a reservoir in the Central Catchment, or the new topics emerging on social media and their likelihood of spreading. In the latter case, the tuple content is new tweets or blog posts from social network site users, which must be analyzed using complex logic.
The key driver for the specialization of this generic framework to HCCS is the need for scalable, flexible, real-time response at reasonable cost. By real time, we mean that processing keeps pace with fluctuating data arrival rates, while continuously satisfying soft real-time application-specific tolerances for latency in delivery of analytics results. By scalable, we mean that the system must be able to handle extremely large data volume, as typified by audiovisual data analytics over many camera feeds. By flexible, we mean that the system must gracefully adapt to rapid changes in data arrival rates, the urgency (priority) of particular analytics tasks, and available computational resources.
Today, audiovisual analytics cannot in general be performed in real time, if at all. Over the past four years, however, ADSC’s audiovisual teams have developed many A/V analytics algorithms that are best-of-class in terms of accuracy, and have reached the level of accuracy needed for many practical applications. However, the time to classify the activity taking place in a video clip using ADSC’s high-accuracy algorithms is perhaps 50 times greater than the length of the clip. ADSC is beginning a major push to make those algorithms real time within the next four years, while preserving good accuracy. This proposed project will provide a cloud-based computational framework to help meet that goal.
Although clouds can provide virtually unlimited computing power on demand, achieving real-time response for HCCS tasks will still be highly challenging, and a straightforward port of HCCS applications to the cloud will not suffice for real-time response. Applications will need to run in parallel, sometimes with hardware acceleration (the topic of another HSSP/HCCS project). Further, whether or not threats actually materialize, society pays the cost for safety and security measures. Since audiovisual data processing is compute-intensive and bandwidth hungry, minimization of resource usage merits extensive attention.
Our solution approach for providing real-time HCCS analytics at reasonable cost rests on three pillars, all to be embodied in Resa: (1) a multi-stage architecture that supports data reduction as close as possible to where data is generated, while globally and dynamically optimizing resource usage; (2) a developer-friendly programming paradigm for HCCS applications on the cloud; and (3) techniques for fault-tolerance that will provide acceptable accuracy and cost for HCCS data analytics. We discuss each of these below.
Multi-stage data reduction. Audio data is large compared to text, and video data is far larger still. For example, we cannot simply ship all surveillance sensor feeds for the CBD to a cloud for processing. This part of the project will address the following research questions:
- What are appropriate data reduction stages for common large-scale real-time HCCS analytics tasks over audiovisual data and social-media text data, such as surveillance-related analytics?
- How can we minimize the data transmitted between stages, through high-performance semantic compression techniques and appropriate use of temporal correlations?
- How can we dynamically optimize the choice and geographical placement of data reduction computational stages, given the priority/ “interestingness” of recent analytics results from a particular sensor?
- Within each stage, how can we design HCCS analytics algorithms to dynamically adapt to the amount of computational resources available at the moment, rather than requiring a fixed amount of resources at all times?
Appropriate programming paradigms. Current distributed stream processing systems were designed to handle straightforward analytics tasks, such as collecting simple aggregates over specific domains. To support the complex analytics associated with challenging data types, e.g., video, audio and text, we must redesign the architecture for distributed stream processing and develop new techniques to support the analytics models used in new applications. This part of the project will address the following research questions:
- How should complex analytics operations be supported in a distributed stream processing engine, in a manner that allows relatively fine-grained parallelism and highly effective, low-overhead support for load balancing?
- How can we evolve the MapReduce programming model to support real-time HCCS analytics, i.e., non-batch jobs with soft deadlines?
- How can computational resources be added to or removed from a running job, so that the cloud is truly elastic for HCCS analytics?
- How can key building blocks for HCCS analytics, such as clustering, outlier detection, and sparse representation, be provided efficiently under a cloud computing paradigm? What other building blocks are needed?
Analytics accuracy and fault tolerance. In large-scale, low-cost cloud computing, faults in computational nodes and associated loss of intermediate data and results are common and unavoidable. We must be able to tolerate this loss of data and still guarantee analytics result accuracy, within a given tolerance (e.g., the loss of occasional video data frames is often acceptable). This part of the project will determine what approaches to fault tolerance are appropriate for cloud-based stream processing for HCCS analytics tasks. More precisely, we will examine the following research questions:
- Under what circumstances are the strategies of replication, checkpoint/ restart, recomputation, and ignoring the failure appropriate?
- How can the aforementioned strategies be combined gracefully in a cloud-based stream processing system for HCCS analytics data?
- How can the system gracefully migrate between combinations of strategies, as circumstances change?