My research interests lie, broadly, in the area of Computer Architecture. To be more specific, my main research work is in Reliability, Approximate Computing and Hardware/Software Mechanisms for Error-Efficient Computing. The over-arching goal of my thesis is to build systematic frameworks that enable efficient, automatic and scalable employment of error-efficient/approximate computing for improved performance, reduced energy consumption and better resiliency.
Please see my Research Statement for more details.
Overview
The end of conventional technology scaling has led to notable interest in techniques that improve overall system efficiency by allowing the system to make controlled errors. Such systems can be considered error-efficient: they only prevent as many errors as they need to. Allowing the system to make selected user-tolerable errors, when exact computation is expensive, can lead to significant resource savings. For example, the emergent field of approximate computing considers a deliberate, but controlled, relaxation of correctness for better performance or energy savings. Similarly, the prohibitive cost of traditional hardware resiliency solutions has led to significant research in alternative low-cost, but less-than-perfect, resiliency solutions that let some hardware errors escape as (user-tolerable) output corruptions.
Error-efficient computing paradigms have the potential to significantly change the way we design hardware and software (current systems are designed for exact computations). However, their widespread adoption depends on developing a fundamental and precise understanding of how errors in computation and data affect the output of a given program. With this understanding, researchers can begin to build ecosystems that enable error-efficient computing in a general and automatic fashion, while providing quality-of-service guarantees to the end-user.
My research furthers the state-of-the-art in this domain in three broad ways: (1) by developing fast, efficient and automatic tools to extract comprehensive and accurate error profiles of general-purpose applications, (2) exploiting these error profiles to enable approximate computing and ultra-low cost hardware resiliency and (3) improving fundamental understanding of how applications/systems behave when perturbed by errors.
Selected Projects
Below are selected projects I have worked on.
1) Approxilyzer: Framework for Application-Level Error Analysis
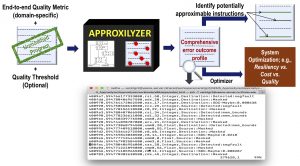
Approxilyzer is an error analysis tool that significantly furthers the state-of-the-art to determine the impact of errors on program output. Approxilyzer, for the first time, enumerates the impact of a single-bit transient error on the program’s end-to-end output quality, for virtually all dynamic instructions in a program, with high accuracy (>95% an average) and precision (within 2% error margin). It employs a hybrid technique of program analysis and (relatively few) error injections to accomplish this. Furthermore, it places the absolute minimum burden on the user/programmer (all other techniques in the literature rely on some programmer intervention).
Using the application’s error profile generated by Approxilyzer, the system or end-user can make precise trade-offs in output quality, energy, resiliency, performance or other system resources.
For example, Approxilyzer can be used to quantitatively tune output quality vs. resiliency vs. overhead to enable ultra-low cost resiliency solutions. We show that if the system/user is willing to tolerate a very small loss in output quality (1%) then the reduction in resiliency overhead can be significant (up to 55%), while still providing protection from 99% of silent data corruptions (SDCs).
A program’s error profile can be used to provide a first- order estimate of its approximation potential in an automated way (no expert knowledge required). The error profile can be used to identify promising subsets of approximable instructions and/or data for further targeted analysis by programmers or other tools. For example, we show that, on average, static instructions resulting in up to 36% of dynamic instructions in our applications, are candidates for approximation.
A fully open-source implementation of Approxilyzer built on top of the popular gem5 simulator, called gem5-Approxilyzer, has been made publicly available (https://github.com/rsimgroup/gem5-approxilyzer). gem5-Approxilyzer enables future extensions of Approxilyzer techniques to applications compiled to different architectures.
2) Minotaur: Adapting Software Testing Methodology for Principled Error Analysis
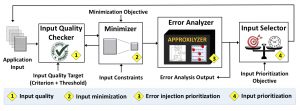
Robust error analysis (the process of extracting an application’s error profile) is time consuming even for a single execution on a given input. For improved confidence, scalability and commercial acceptability, such error analyses must be performed over a range of workloads and input values that make them impractical in most cases. To address this problem, we developed a novel toolkit called Minotaur. Minotaur uses the insight that analyzing a program’s execution for error is similar to testing it for software bugs. Minotaur applies software-testing methodologies (test-case quality, test-case minimization and test-case prioritization) to significantly improve the speed and efficiency of error analyses techniques. Minotaur improves the speed of comprehensive error analysis by 4x, on average, over state-of-the-art tools like Approxilyzer. These gains go up to 39x when the error analysis is targeted to specific techniques like resiliency or approximate computing.
3) Interactions of Software Approximations and System Resiliency
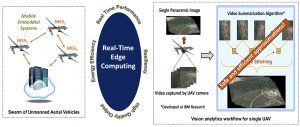
Applying approximate computing techniques may especially be beneficial in the emerging domain of edge computing where mission-critical and cognitive applications have demanding real-time, energy, and reliability requirements. This domain has many applications that are both military and civilian in nature, such as Unmanned Aerial Vehicles (UAV), connected cars, industrial robotics, etc. Algorithms used in these systems have many aspects of Cognitive Computing — event and coverage summarization, detection, tracking of moving objects etc. — that make them ideal candidates for approximations. My work (in collaboration with IBM research) shows that approximate computing is very lucrative in this domain (yielding performance and energy gains up to 68%). However, it is unclear how these approximations affect the overall reliability of the system. To the best of my knowledge, this work is the first to look at the interaction between software approximations and hardware resiliency for a state-of-the-art vision analytics workload used aboard unmanned aerial vehicles (UAVs). We show that it is possible to design approximate algorithms for this domain that provide significant performance and energy benefits while preserving the overall system reliability.