About The Project
The Next-Generation Compilers and Architectures for Computation Acceleration with Energy Efficiency research project is conducted at Advanced Digital Sciences Center (ADSC) as part of the Data Analytics subprogram. The Principal Investigator leading our research effort is Professor Deming Chen from University of Illinois at Urbana-Champaign.
A. Introduction
One of ADSC’s central goals at the beginning is to enable Immersive Virtual Reality. Such applications can play essential roles to facilitate humans to interact with the digital world in a seamless and natural manner, as envisioned by the Human Sixth Sense Program (HSSP) in ADSC. However, the majority of the related Digital Signal Processing (DSP) algorithms have been previously implemented in software running on CPUs, which might not be fast enough or the most energy efficient. This was the motivation for PI Chen to propose using either FPGAs or GPUs to speed up the kernel computations of the relevant DSP algorithms three year ago. Through a collaborative effort within ADSC, we demonstrated that FPGAs and GPUs could provide a significant amount of speedup and improvement for energy efficiency. The initial achievements from previous project illustrate a great potential for GPUs and FPGAs to tremendously speed up multimedia applications with high energy efficiency.
However, it is also apparent that exploiting the computing resources in these accelerators for higher performance and lower energy is in most cases far away from being a push-button process. Programming models for GPUs and FPGAs are completely isolated and disjoint. Efficient programming of both architectures requires widely different skills. To get the best performance from different platforms, programmers have to come up with specialized implementations targeting each architecture. Our initial FCUDA effort [1-4] tackled these challenges from the head on. We developed appropriate translation systems to compile parallel programs in CUDA (a GPU language) into customized parallel execution on FPGAs. Such a flow offers several major advantages. First, it allows application developers to use a common programming model for both GPUs and FPGAs in a heterogeneous platform (such as [16]), which simplifies application development. Second, due to CUDA’s wide adoption and popularity, a large body of existing applications written in CUDA would be available for FPGA acceleration. Third, applications that do not gain much benefit from GPU execution can be retargeted to FPGAs for potentially better acceleration. Fourth, it will enable very rapid and easy evaluation of a large amount of parallel algorithms. FPGAs traditionally have a complex design flow and have required programming using low-level hardware languages. This is starting to change with research in high-level synthesis (HLS) tools that map higher level programming models onto FPGAs, thereby improving design productivity tremendously. Driven by the same motivation, we also started to develop HLS techniques that drastically improve the efficiency of FPGA programming with high design quality [8-12].
GPUs have gained importance as one of the primary computation units used for acceleration of highly data-parallel computation functions. In the desktop and portable computer markets, GPUs are now ubiquitous; every system has a graphics processor for display, and these GPUs also support general purpose computations (GPGPU) through the CUDA and OpenCL languages. However, although these languages are widely used, optimizing program implementations is not a trivial task. GPGPU optimization requires in-depth knowledge of the GPU’s architecture. In the past three years, we have worked on new GPU compiler techniques for higher performance considering unique GPU architectural features, including control flow divergence optimization [5], register and thread co-optimization [6], and GPU kernel scheduling [7]. We also explored GPU acceleration targeting a specific application relevant to ADSC’s central research theme [13][14]. However, we have not worked on power and energy optimization for GPUs mainly due to a lack of sufficiently accurate GPU power/energy estimation tools and insufficient knowledge of the internal characteristics of the GPU architecture. Fortunately, the GPGPU-sim tool was recently extended with power and energy modeling features to become GPUWattch, the first cycle-accurate power and energy modeling software for GPU architectures [15], which would pave the way for our new power/energy-centric GPU research.
B. Project Goals
We group the goals of this project into two big research lines.
B.1. FPGA and HLS
For this line of research, we set two new thrusts based on the past success:
- A complete and mature CUDA (and OpenCL) to FPGA compilation flow supporting various types of FPGA on-chip communication scenarios, thus achieving scalable high-performance FPGA solutions;
- A continued development of the new HLS engine that would outperform the best state-of-the-art algorithms and solutions.
Our eventual target is to develop a complete open source academic design flow consisting of two components: CUDA/OpenCL to C code translation and an HLS flow that compile C/C++ code to RTL (register-transfer level) implementation for FPGA. The C/C++ to RTL flow by itself would be a standalone package. Such a path would offer modular solutions that provide important and unique flexibility for input language choices and generate FPGA solutions serving various purposes – whether they are comparing GPU/FPGA performance/energy, leveraging common languages to program both GPUs and FPGAs, or simply converting an existing C/C++ software solution to FPGA. After releasing such an open source design flow, we would also put together a commercial license so interested companies can have a chance to use it for their design purposes with a license fee.
B.2. GPU
We set two new thrusts in this line of research:
- Advanced GPU compiler and architecture study for low energy applications;
- Novel implementations of important multimedia applications onto GPUs.
For the first thrust, we will carry out a wide range of scheduler, compiler and architectural research to optimize power and energy consumption and properly consider tradeoffs among performance, instantaneous power consumption, and total energy consumption. For the second thrust, we will mainly focus on the applications in the embedded system projects of I2R (the Institute for Infocomm Research), especially the social robotic program, which fits into ADSC’s HSSP theme as well. There will be nice synergy between the two thrusts above. For thrust 2, in an ongoing collaboration with I2R, we will develop computer vision, audio direction finding, and intelligence algorithms for implementation in an embedded environment. With this real-world driving application, we can effectively demonstrate the impact of the fundamental research of thrust 1.
C. Research Approach and Methodology
C.1. CUDA/OpenCL to FPGA Compilation
CUDA and OpenCL are the two programming models targeting GPU architectures. CUDA targets NVIDIA GPUs while OpenCL is an open standard. We already developed a CUDA-to-FPGA compilation flow [1-4] and generated quite some interest in the research community (initial works [1][2] together have been cited more than 60 times so far). Recently, OpenCL is gaining popularity being an open and platform-independent standard. In this project, we will adapt our existing FCUDA flow to map OpenCL kernels onto FPGA hardware. Figure 1 demonstrates the new flow.
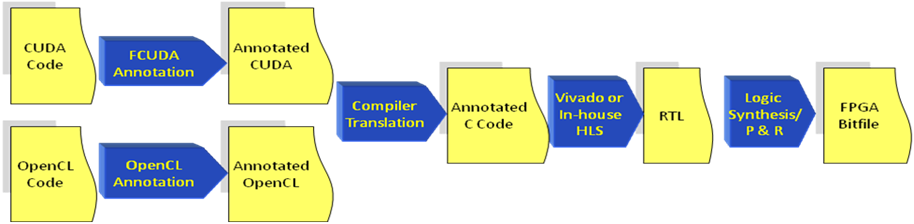
Figure 1. Complete CUDA/OpenCL to FPGA Flow with In-house HLS Tool
The design inputs can be captured using either CUDA or OpenCL, which then are annotated with compiler pragmas for coarse-grained parallelism extraction. The output from the initial pass is Vivado compatible C code. Vivado HLS will then extract the fine-grained parallelism and generate the RTL design. In the long-term, we propose to integrate this compiler framework with our in-house HLS C/C++ to RTL tool that is under development and is also part of this project (refer to C.2). The new in- house HLS tool will input the annotated C code and handle all the pragmas to generate optimized hardware. A detailed and systematic study will be performed using a set of HLS benchmarks to compare the hardware generated from Vivado and in-house HLS tool.
With the ever-increasing capacity of modern FPGAs, communication between numerous hardware cores within an FPGA is becoming a key challenge. Traditional communication architectures such as shared buses are inefficient since only one source can drive the bus at any instant. They do not scale well with the increasing number of cores and provide limited bandwidth. A network-based fabric provides potential solution to both these issues. Network-on-Chips (NoCs) [17-23] provide a regular and structured on-chip communication mechanism and are inherently scalable. NoCs are also flexible and offer more bandwidth than bus-based architectures. Also, NoCs have been shown to use less power than buses through shorter wires. We propose to develop and architect a novel NoC architecture for FPGA with the specific goal of improving the performance of cores generated by our FCUDA/FOpenCL compilation framework.
C.2. New HLS Engine
In this thrust, we will address several challenges in HLS:
- Achieve timing closure to meet the designer’s timing constraints or deliver maximal performance.
- Meet the resource usage constraints or minimize the resource usage to maximize the spatial parallelism.
- Exploit the fine-grained parallelism provided by FPGA.
C.3. Advanced GPU Compiler and Architecture
We propose three subtasks in this thrust that would cooperate to achieve low power/energy-centric GPU solutions.
C.3.a. Scheduler level optimization
GPU kernels are designed for highly data-parallel computation. However, not all kernels or kernel calls require full use of the GPU: memory bound kernels may need only a subset of GPU resources to saturate performance, and some kernels may only require a subset of resources for the entire call. In our prior work [7], we demonstrated modeling and scheduling of resources for concurrent kernel execution that improves total runtime by scheduling memory-bound and computation-bound kernel concurrently. In large scale systems, the system may be sharing hundreds or thousands of GPUs among tens of thousands of simultaneous applications, we propose to:
- Develop decentralized queuing and workload distribution methods that distribute GPU kernels into independent queues that can efficiently schedule kernels concurrently;
- Develop methods for workload distribution that can properly order kernel dependencies while maximizing inter-kernel parallelism and minimizing communication overhead between dependent kernel instances;
- Automate kernel splitting and merging to improve workload distribution granularity and improve expressed parallelism.
In addition, we plan to extend our computation model to include real-time kernel scheduling for embedded devices. We will study scheduler level optimization of power and energy that would produce codes that can use DVFS, clock gating, and power gating as well as an underlying architecture (refer to subtask (3)) with efficient and fine-grained support for these features.
C.3.b. Compiler level optimization
Based on our prior work for joint register and thread optimization [6] and elimination of control flow divergence [5], we have identified a few new concrete directions:
- Memory overlap optimization through use of the graph coloring techniques we developed for our FCUDA tool [3].
- Memory space optimization through analyzing the use patterns of different memory structures in order to automatically move data structures into the texture and scratchpad memories that are typically under-utilized. Automating this remapping improves memory bandwidth utilization, data locality and lowers power and energy consumption through localization of communication.
- Memory coalescing optimization which ensures efficient use of the memory bandwidth through appropriately grouping memory requests together into a single transaction.
In addition, these performance optimizations can be adapted for power and energy optimization through use of a detailed power and energy model of the GPU microarchitecture. We will develop power and energy models integrated into the GPU compiler so that the implications of each transformation can be quantified and evaluated to meet power, performance and energy constraints. Furthermore, compilation can produce kernels that avoid using high-power consuming functional units, thus enabling frequent clock and power gating. Thus, we also plan to integrate scheduler- directed compilation to use compiler-level optimizations in order to produce codes that are friendly to scheduler policies, particularly for DVFS, clock gating and power gating techniques that can save significant power and energy consumption.
C.3.c. Architectural optimization
There is significant opportunity to improve the power and energy consumption of GPU architectures. Current GPU architectures support multiple voltage and frequency settings, which can be used for traditional DVFS. However, this is only at the level of the entire GPU – when multiple kernels are sharing GPU resources, we cannot individually scale voltage and frequency of portions of the GPU architecture. The granularity of DVFS is an important design point – fine-grained DVFS gives more design and use flexibility, but increases area overhead to implement independent power and clock supply circuitry as well as multi-clock domain crossing circuitry. Coarse-grained DVFS reduces overheads, but gives less flexibility in scaling performance and power/energy consumption. Clock gating and power gating are widely used low-level architectural optimizations for reducing power consumption by turning off unused portions of the GPU. However, like DVFS, the granularity of this circuitry is an important design consideration as well. Furthermore, clock gating and power gating require sophisticated control to turn portions of the circuitry on and off without affecting kernel correctness or performance. We will explore these architectural design dimensions for power/energy-efficient GPU architecture design.
C.4. GPU Implementation of Multimedia Applications
We started a collaborative effort with researchers from I2R on their social robotic program. Their robot is currently connected to a PC, which is not ideal for mobility. To overcome this issue, we have done initial feasibility studies for board-level solutions. For a face detection algorithm I2R provided, we mapped their code into GPU using OpenCV (an open source and standard computer vision library) and tested the performance using their datasets (160×120 and 320×240 color videos). We obtained ~5x and ~13x speedup for respective resolutions.
Through this feasibility study, we identified that the existing GPU version of OpenCV has a number of limitations. The GPU version does not produce the exact same output as the CPU version. For example, in our experiment with a low-resolution (160×120) video, GPU failed to detect the face object in 10% of total frames and showed false positive in 8% of total frames. With further investigation, we found that OpenCV GPU’s face detection code implements a different algorithm flow. In the CPU version, the scaling steps work on the classifier scan window. During iterations, the window size is upscaled by a scale factor. For the GPU version, the image is scaled down while the window size remains fixed. As illustrated in Figure 2, this algorithm implies worse detection rates for smaller (or far away) faces.

Figure 2: Comparison of CPU-GPU Face Detection Algorithms
This motivates us to carry out the following studies:
- Implement high-quality vision algorithms on GPUs while exploring new GPU features that could make such implementations feasible, such as dynamic parallelism. Other key optimization strategies such as memory coalescing, data layout transformation, and thread/memory /register co-optimization would be explored as well.
- We will analyze how memory accesses, resource allocations, and scheduling affect the power and energy consumption of applications. This study can be facilitated through GPUWattch [15]. Once such a model is built, we will then carry out algorithm re-design, data re- organization, and suitable memory access patterns to optimize power and energy. This effort will connect with advanced GPU compiler and architecture topic as well to evaluate how the techniques proposed there would help for mapping these applications more efficiently.
- We will study topics in video/computer vision and audio applications, such as speaker recognition, eye detection, body-pose recognition, human motion recognition, facial expression/emotion, etc.
- We will pursue board-level solutions to replace the PC connected with the robot currently. One possibility is the Jetson TK1 embedded platform [24]: an embedded platform that has ARM and Kepler-based GPU processors integrated in a single SoC.
Current Progress
We have accomplished some works and published few papers at FPL 2013, FPGA 2014, and FCCM 2014. We also have submitted another conference and 2 journal papers.
References
[1] Papakonstantinou, K. Gururaj, J. Stratton, D. Chen, J. Cong, and W.M. Hwu, “FCUDA: Enabling Efficient Compilation of CUDA Kernels onto FPGAs,” Proceedings of IEEE Symposium on Application Specific Processors, pp. 35-42, July 2009. (Best Paper Award)
[2] A. Papakonstantinou, Y. Liang, J. Stratton, K. Gururaj, D. Chen, W.M. Hwu and J. Cong, “Multilevel Granularity Parallelism Synthesis on FPGAs,” Proceedings of IEEE International Symposium on Field-Programmable Custom Computing Machines, May 2011. (Best Paper Award)
[3] A. Papakonstantinou, D. Chen, W.M. Hwu, J. Cong, and Y. Liang, “Throughput-oriented kernel porting onto FPGAs,” Proceedings of IEEE/ACM Design Automation Conference, June 2013.
[4] S. Gurumani, K. Rupnow, Y. Liang, H. Cholakkail, and D. Chen, “High Level Synthesis of Multiple Dependent CUDA Kernels for FPGAs,” Proceedings of IEEE/ACM Asia and South Pacific Design Automation Conference, January 2013. (Invited)
[5] Z. Cui, Y. Liang, K. Rupnow, and D. Chen, “An Accurate GPU Performance Model for Effective Control Flow Divergence Optimization”, Proceedings of IEEE International Parallel & Distributed Processing Symposium, May 2012.
[6] Y. Liang, Z. Cui, K. Rupnow, and D. Chen, “Register and Thread Structure Optimization for GPUs,” Proceedings of IEEE/ACM Asia and South Pacific Design Automation Conference, January 2013.
[7] Y. Liang, H. P. Huynh, K. Rupnow, R. Goh, and D. Chen, “Efficient Concurrent Kernel Execution on GPUs”, Proceedings of Workshop on SoCs, Heterogeneous Architectures and Workloads, February, 2013.
[8] K. Rupnow, Y. Liang, Y. Li, and D. Chen, “A Study of High-Level Synthesis: Promises and Challenges”, IEEE International Conference on ASIC, October 2011. (Invited)
[9] K. Rupnow, Y. Liang, Y. Li, D. Min, M. Do, and D. Chen, “High Level Synthesis of Stereo Matching: Productivity, Performance, and Software Constraints”, IEEE International Conference on Field-Programmable Technology, December 2011. (Best Paper Nomination)
[10] Y. Liang, K. Rupnow, Y. Li, D. Min, M. Do, and D. Chen, “High Level Synthesis: Productivity, Performance and Software Constraints”, Journal of Electrical and Computer Engineering, Special Issue on ESL Design Methodology. Volume 2012, Article ID 649057, 14 pages, 2012.
[11] W. Zuo, Y. Liang, K. Rupnow, P. Li, D. Chen, and J. Cong, “Improving High Level Synthesis Optimization Opportunity Through Polyhedral Transformations,” Proceedings of ACM/SIGDA International Symposium on Field Programmable Gate Arrays, February 2013.
[12] H. Zheng, S. Gurumani, L. Yang, D. Chen, K. Rupnow, “High-level Synthesis with Behavioral level Multi-Cycle Path Analysis,” Proceedings of IEEE International Conference on Field Programmable Logic and Applications, September, 2013.
[13] Y. Liang, Z. Cui, S. Zhao, K. Rupnow, Y. Zhang, D. L. Jones, and D. Chen, “Real-time Implementation and Performance Optimization of 3D Sound Localization on GPUs”, Proceedings of IEEE/ACM Design, Automation & Test in Europe, March 2012.
[14] S. Zhao, S. Ahmed, Y. Liang, K. Rupnow, D. Chen and D. L. Jones, “A Real-Time 3D Sound Localization System with Miniature Microphone Array for Virtual Reality,” Proceedings of IEEE Conference on Industrial Electronics and Applications, July 2012.
[15] Jingwen Leng, Syed Gilani, Ahmed El-Shafiey, Tayler Hetherington, Nam Sung Kim, Tor M. Aamodt, and Vijay Janapa Reddi, “GPUWattch: Enabling Energy Optimization in GPGPUs,” IEEE/ACM Int. Symp. on Computer Architecture, June 2013.
[16] M. Showerman, J. Enos, A. Pant, V. Kindratenko, C. Steffen, R. Pennington, W. Hwu, “QP: A Heterogeneous Multi-Accelerator Cluster,” Proceedings of 10th LCI International Conference on High-Performance Clustered Computing, 2009.
[17] Bafumba-Lokilo, David; Savaria, Y.; David, J.-P., “Generic crossbar network on chip for FPGA MPSoCs,” Proceedings of Joint 6th International IEEE Northeast Workshop on Circuits and Systems and TAISA Conference, pp.269-272, June 2008.
[18] M. E. S. Elrabaa and A. Bouhraoua, “A hardwired NoC infrastructure for embedded systems on FPGAs,” Proceedings of Microprocessors and Microsystems – Embedded Hardware Design, vol. 35, no. 2, pp. 200–216, 2011.
[19] Abdelfattah, M.S.; Betz, V., “Design tradeoffs for hard and soft FPGA-based Networks- on-Chip,” Proceedings of International Conference on Field-Programmable Technology (FPT), pp.95-103, December 2012.
[20] R. Gindin, I. Cidon, and I. Keidar, “NoC-based FPGA: Architecture and routing,” Proceedings of First International Symposium on Networks-on-Chip NOCS, pp. 253–264, 2007.
[21] Yun Jie Wu; Houzet, D.; Huet, S., “A Programming Model and a NoC-Based Architecture for Streaming Applications,” Proceedings of 13th Euromicro Conference on Digital System Design: Architectures, Methods and Tools (DSD), pp.393-397, September 2010.
[22] Fernandez-Alonso, E.; Castells-Rufas, D.; Risueno, S.; Carrabina, J.; Joven, J., “A NoC- based multi-{soft}core with 16 cores,” Proceedings of 17th IEEE International Conference on Electronics, Circuits, and Systems (ICECS), pp.259-262, December 2010.
[23] B. Sethuraman, P. Bhattacharya, J. Khan, and R. Vemuri, “LiPaR: A light-weight parallel router for FPGA-based networks-on-chip,” Proceedings of the 15th ACM Great Lakes symposium on VLSI, New York, 2005.
[24] NVIDIA Jetson TK1 Platform. https://developer.nvidia.com/jetson-tk1.