Histograms
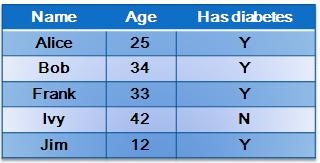
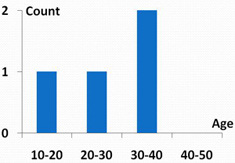
Assume we have a database of medical records from a specific hospital, where ‘Y‘ or ‘N’ denotes whether a person has diabetes or not. If the hospital intends to directly release a statistical report on the age distribution of diabetic patients in the database (see the histogram below), private information of individuals may be leaked. For example, if the adversary happens to know that Alice is the only person aged between 20 and 30 years in the hospital, he can confirm that Alice has diabetes. є-differential privacy enables the release of sensitive data and protect the privacy of individuals at the same time. The method performs random perturbations on the data before publishing them. The perturbation ensures that the presence or absence of any particular record has little impact on the noisy data. A large value for the parameter є indicates stronger privacy protection, but also higher amount of noise added to the data.
|
|
Motivated by this, we propose two novel algorithms, namely StructureFirst and NoiseFirst for computing high-accuracy DP histograms. The former decides the histogram structure before injecting noises required by DP, while the latter reverses the order of these steps. In particular, both NoiseFirst and StructureFirst rely on the commonly used and well-studied histogram technique on data compressionand summarization. While traditional histogram only intends to merge neighboring similar counts to save storage space, we show that it is also helpful to reduce the sensitivities of the synopsis with respect to privacy attacks. This advantage leads to effective cutdown on the random noises for privacy protection purpose and improves the accuracies of queries based on the histogram of published data. Despite of the benefits from the histogram synopsis, the construction of optimal histogram raises new challenges, because of the potential privacy information exposed with the public structure of the histogram. To avoid any privacy leakage, we propose some new strategies to protect the structural information of the histograms. To meet the requirements from more complicated queries, we also present how to enhance the effectiveness of histogram synopsis for range query processing. Extensive experiments, using several real data sets, confirm that the proposed methods output highly accurate query answers, and consistently outperform existing competitors.
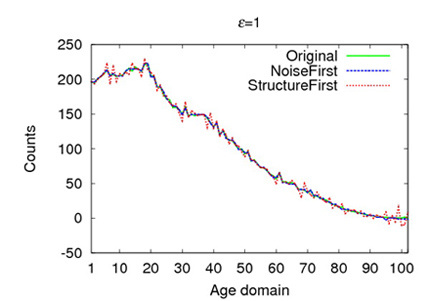
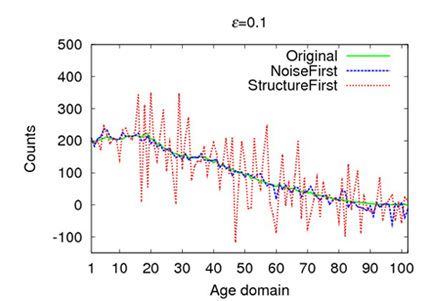
In the following Figures, green lines show the original distributions of people’s ages which is derived from the census records of individuals in Brazil. Blue lines and red lines exhibit the perturbed distributions produced by PreDP and PostDP separately. A larger є implies bigger noises. Based on the observations of the following figures, NoiseFirst produces smaller deviation from the original distribution and thus performs outstanding for unit-lengh count queries (e.g., querying the number of people whose ages are within[20, 25]). StructureFirst , on the other hand, has advantages with most settings of the query lengths. The NoiseFirst, to the best of our knowledge, is the 1st approach that can outperform Dwork et al.’s method with respect to the unit-length queries. This provides us a possibility to make a better visualization of the statistic data in a user interface. On the other hand, a query executer can provide the users more precise results by querying the DP-complaint histogram published by the StructureFirst approach. Thus, our NoiseFirst and StructureFirst approaches is not exclusive with each other. Particularly, they can be simultaneously embedded into a mainstream DBMS to better serve the users in different modules.
|
|
Publications
- J. Xu, Z. Zhang, X. Xiao, Y. Yang, G. Yu and M. Winslett. Differentially Private Histogram Publication. VLDB J., to appear.
- J. Xu, Z. Zhang, X. Xiao, Y. Yang and G. Yu. Differentially Private Histogram Publication. ICDE, 2012.