Data Cubes
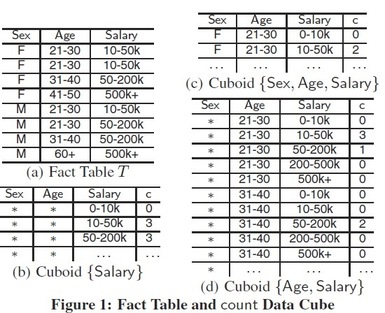
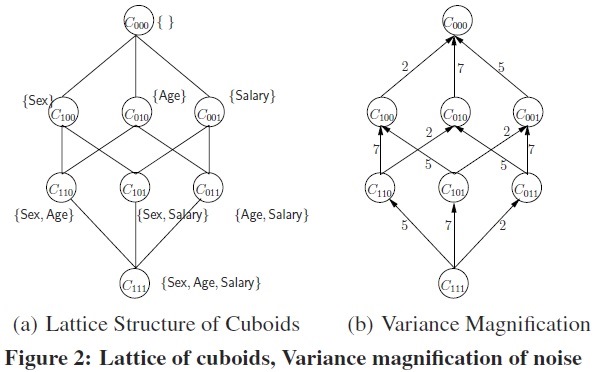
Data cubes play an essential role in data analysis and decision support. In a data cube, data from a fact table is aggregated on subsets of the table’s dimensions, forming a collection of smaller tables called cuboids. When the fact table includes sensitive data such as salary or diagnosis, publishing even a subset of its cuboids may compromise individuals’ privacy. In this work, we address this problem using differential privacy (DP), which provides provable privacy guarantees for individuals by adding noise to query answers. We choose an initial subset of cuboids to compute directly from the fact table, injecting DP noise as usual; and then compute the remaining cuboids from the initial set. Given a fixed privacy guarantee, we show that it is NP-hard to choose the initial set of cuboids so that the maximal noise over all published cuboids is minimized, or so that the number of cuboids with noise below a given threshold (precise cuboids) is maximized. We provide an efficient procedure with running time polynomial in the number of cuboids to select the initial set of cuboids, such that the maximal noise in all published cuboids will be within a factor (ln |L| + 1)^2 of the optimal, where |L| is the number of cuboids to be published,
or the number of precise cuboids will be within a factor (1 − 1/e) of the optimal. We also show how to enforce consistency in the published cuboids while simultaneously improving their utility (reducing error). In an empirical evaluation on real and synthetic data, we report the amounts of error of different publishing algorithms, and show that our approaches outperform baselines significantly.
|
|
Publication
- B. Ding, M. Winslett, J. Han and Z. Li, Differentially Private Data Cubes: Optimizing Noise Sources and Consistency. SIGMOD, 2011.