Welcome to the DEPEND group homepage at the University of Illinois,
Urbana-Champaign



























The DEPEND group focuses on the research, design, and validation of highly available, reliable, and trustworthy computing systems and networks. The research has two main branches in reliability and security, and health analytics and systems.
The group comprises members from the Departments of Electrical and Computer Engineering and Computer Science, whose expertise spans across hardware and low-level architectures, operating systems and virtualization, cyber-physical systems, health informatics (embedded medical devices, personalized health-care, genomics) and big-data analytics. With a strong experimental focus, we develop techniques and methods that are tested on real systems or verified with actual production data.
Our current collaborations include several industry partners and research institutions; for example, IBM, Cray, Microsoft, Intel, Nokia-Bell Labs, Los Alamos National Lab, NERSC, Sandia National Labs, the National Science Foundation, the Department of Defense, the Department of Energy, and the National Security Agency. For health-related research, we collaborate with Mayo Clinic, the National University Hospital in Singapore, and with industry partners from technical and pharma industries such as Strand Life Sciences, Abbott and Eli Lilly. In the past we had also important collaborations with Sun Microsystems (now Oracle), HP, Motorola, Boeing.
Call for undergrads!
We have a great history of success with undergraduates.
Get in touch with our research members for a brilliant research experience. Visit the “Working with undergraduates” page for the latest updates!
FEATURED RECENT RESEARCH:
V. Saboo, Y. Cao, V. Kremen, V. Sladky, N. M. Gregg, P. M. Arnold, P. J. Karoly, D. R. Freestone, M. J. Cook, G. A. Worrell, R. K. Iyer, “Individualized seizure cluster prediction using machine learning and chronic ambulatory intracranial EEG”, IEEE Transactions on NanoBioscience 2023 https://ieeexplore.ieee.org/document/10122733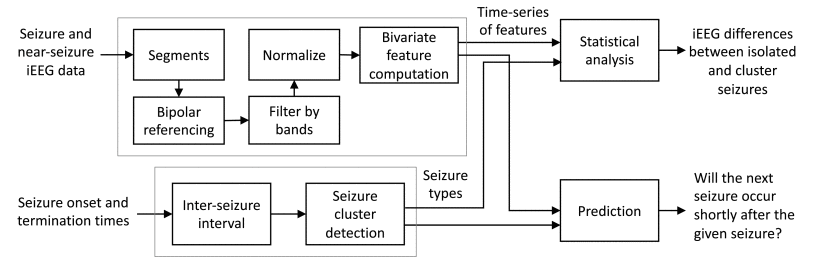
|
| Weichao Mao, Haoran Qiu, Chen Wang, Hubertus Franke, Zbigniew T. Kalbarczyk, Ravishankar K. Iyer, Tamer Başar (2023). Multi-Agent Meta-Reinforcement Learning: Sharper Convergence Rates with Task Similarity. In Proceedings of the 37th Conference on Neural Information Processing Systems (NeurIPS 2023). |
|
|
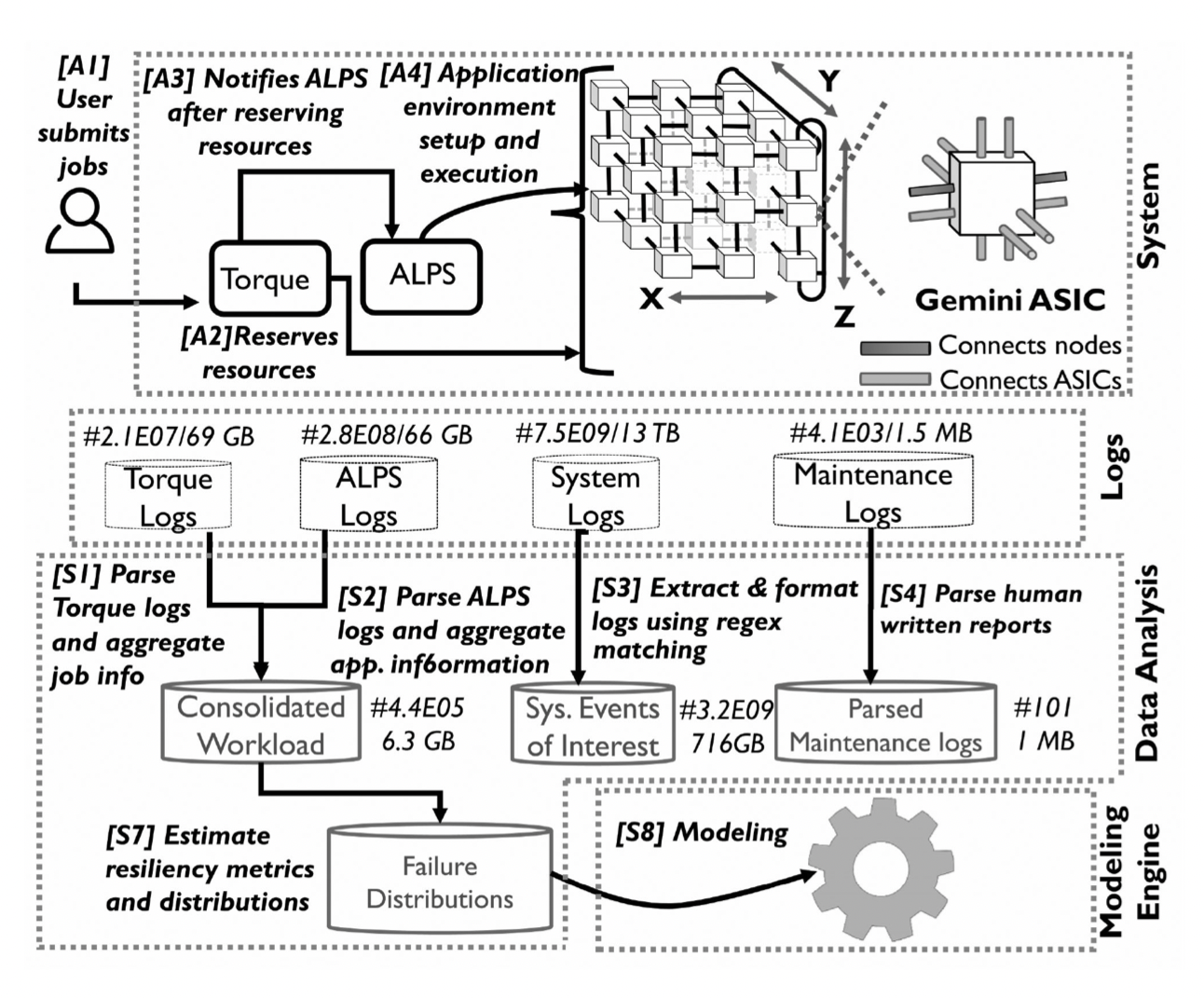 Bentolhoda Jafary, Saurabh Jha , Lance Fiondella, Ravishankar K. Iyer (2021). Data-driven Application-oriented Reliability Model of a High-Performance Computing System. IEEE Transactions on Reliability. https://doi.org/10.1109/TR.2021.3085582 Bentolhoda Jafary, Saurabh Jha , Lance Fiondella, Ravishankar K. Iyer (2021). Data-driven Application-oriented Reliability Model of a High-Performance Computing System. IEEE Transactions on Reliability. https://doi.org/10.1109/TR.2021.3085582 |
Zachary Stephens, Dragana Milosevic, Benjamin Kipp, Stefan Grebe, Ravishankar K. Iyer, Jean-Pierre A. Kocher (2021). PB-Motif—A Method for Identifying Gene/Pseudogene Rearrangements With Long Reads: An Application to CYP21A2 Genotyping. Frontiers in Genetics, 12:716586. https://doi.org/10.3389/fgene.2021.716586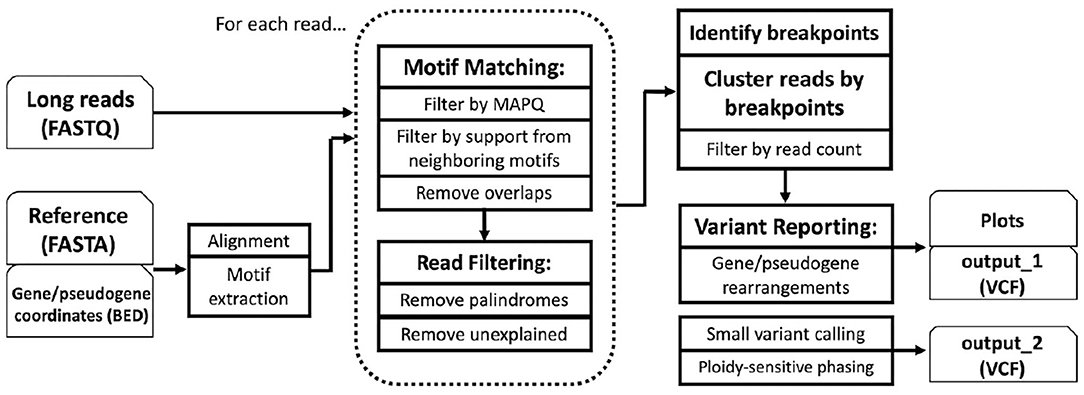 |