Providing transcripts of audio or video content is critical for making these experiences accessible to a wide variety of audiences, especially those who are deaf or hard of hearing. Even those with perfect hearing might prefer to skim over a transcript of text rather than listen to audio sometimes. However, often times the slowest part of the audio and video publishing process is the transcribing portion of the workflow. This was certainly true with the recent interview I did with Ted Underwood, which I conducted on March 2 but did not release until March 31. The majority of that time was spent transcribing the interview; editing and quality control were significantly less time consuming.
Theoretically, one way we could speed up this process is to have computers do it for us. Over the years I’ve had many people ask me whether automatic speech-to-text transcription is a viable alternative to human transcription in dealing with oral history or podcast transcription. The short answer to that question is: “sort of, but not really.”
Speech to text or speech recognition technology has come a long way particularly in recent years. Its performance has improved to the point where human users can give auditory commands to a virtual assistant such as Alexa, Siri, or Google Home, and the device usually gives an appropriate response to the person’s request. However, recognizing a simple command like “Remind me at 5 pm to transcribe the podcast” is not quite the same as correctly recognizing and transcribing a 30-minute interview. It has to handle differences between two speakers and lengthy blocks of text.
To see how good of a job the best speech recognition tools do today, I decided to have one of these tools attempt to transcribe the Ted Underwood podcast interview and compare it to the actual transcript I did by hand. The specific tool I selected was Amazon Transcribe, which is part of the Amazon Web Services (AWS) suite of tools. This service is considered one of the best options available and uses cloud computing to convert audio data to textual data, presumably like how Amazon’s Alexa works.
It’s important to note that Amazon Transcribe is not free, however, it only costs $0.0004 per second of text, so Ted Underwood’s interview only cost me 85 cents to transcribe. For more on Amazon Transcribe’s costs, see this page.
In any case, here is a comparison between my manual transcript vs. Amazon Transcribe. To begin, here is the intro to the podcast as spoken and later transcribed by me:
Ben Ostermeier: Hello and welcome back to another episode of “It Takes a Campus.” My name is Ben, and I am currently a graduate assistant at the Scholarly Commons, and today I am joined with Dr. Ted Underwood, who is a professor at the iSchool here at the University of Illinois. Dr. Underwood, welcome to the podcast and thank you for taking time to talk to me today.
And here is Amazon Transcribe’s interpretation of that same section of audio, with changes highlighted:
Hello and welcome back to another episode of it takes a campus. My name is Ben, and I am currently a graduate assistant at Scali Commons. And today I'm joined with Dr Ted Underwood, who is a professor at the high school here at the University of Illinois. Dr. Underwood, welcome to the podcast. Thank you for taking time to talk to me today.
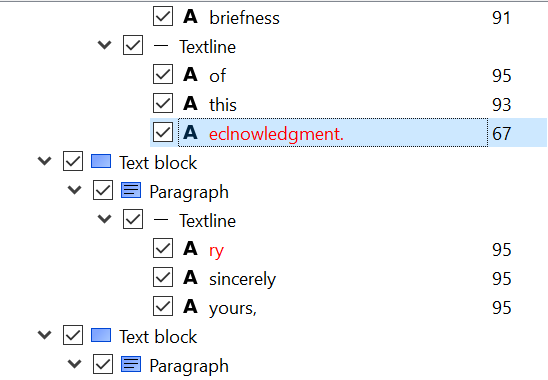
As you can see, Amazon Transcribe did a pretty good job, but there are some mistakes and changes from the transcript I hand wrote. It particularly had trouble with proper nouns like “Scholarly Commons” and “iSchool,” along with some minor issues like not putting a dot after “Dr” and missing an “and” conjunction in the last sentence.

Screenshot of text comparison between Amazon-generated (left) and human-generated (right) transcripts of the podcast episode.
You can see the complete changes between the two transcripts at this link.
Please note that the raw text I received from Amazon Transcribe was not separated into paragraphs initially. I had to do that myself in order to make the comparison easier to see.
In general, Amazon Transcribe does a pretty good job in recognizing speech but makes a decent number of mistakes that require cleaning up afterwards. For me, I actually find it faster and less frustrating to transcribe by hand instead of correcting a ‘dirty’ transcript, but others may prefer the alternative. Additionally, in some cases an institution may have a very large number of untranscribed oral histories, for example, and if the choice is between having a dirty transcript vs. no transcript at all, a dirty transcript is naturally preferable.
Also, while I did not have time to do this, there are ways to train Amazon Transcribe to do a better job with your audio, particularly with proper nouns like “Scholarly Commons.” You can read more about it on the AWS blog.
That said, there is very much an art to transcription, and I’m not sure if computers will ever be able to totally replicate it. When transcribing, I often have to make judgement calls about whether to include aspects of speech like “um”s and “uh”s. People also tend to start a thought and then stop and say something else, so I have to decide whether to include “false starts” like these or not. All of these judgement calls can have a significant impact on how researchers interpret a text, and to me it is crucial that a human sensitive to their implications makes these decisions. This is especially critical when transcribing an oral history that involves a power imbalance between the interviewer and interviewee.
In any case, speech to text technology is becoming increasingly powerful, and there may come a day, perhaps very soon, when computers can do just as good of a job as humans. In the meantime, though, we will still need to rely in at least some human input to make sure transcripts are accurate.