
This post accompanies our presentation “Immersive multitalker remote microphone system” at the 181st Acoustical Society of America Meeting in Seattle.
In our previous post, which accompanied a paper at WASPAA 2021, we proposed an improved wireless microphone system for hearing aids and other listening devices. Unlike conventional remote microphones, the proposed system works with multiple talkers at once, and it uses earpiece microphones to preserve the spatial cues that humans use to localize and separate sound. In that paper, we successfully demonstrated the adaptive filtering system in an offline laboratory experiment.
To see if it would work in a real-time, real-world listening system, we participated in an Acoustical Society of America hackathon using the open-source Tympan platform. The Tympan is an Arduino-based hearing aid development kit. It comes with high-quality audio hardware, a built-in rechargeable battery, a user-friendly Android app, a memory card for recording, and a comprehensive modular software library. Using the Tympan, we were able to quickly demonstrate our adaptive binaural filtering system in real hardware.

The Tympan processor connects to a stereo wireless microphone system and binaural earbuds.
The photo above shows our hardware setup. Two wireless microphones worn by the talkers transmit low-noise speech to a two-channel receiver. The receiver is configured in stereo mode so that each speech signal is routed to its own channel. Because the analog wireless system has nearly zero delay, the transmitted speech signal reaches the processor before the sound reaches the ears. The listener wears a pair of earbuds with one microphone in each ear, so it provides binaural capture and playback. Because we need a total of four microphones, the Tympan is configured with a codec shield with additional inputs.
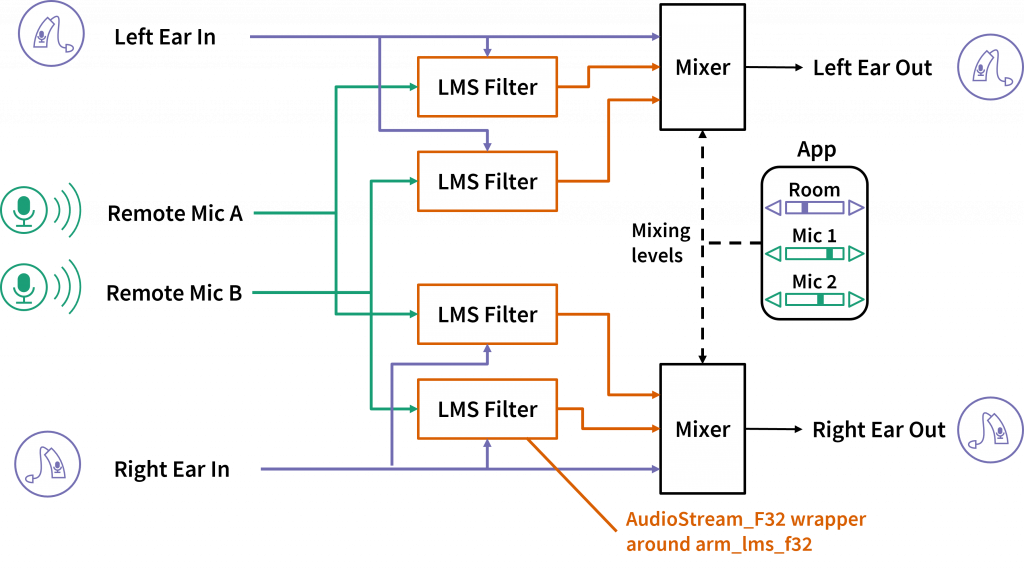
The software implementation uses adaptive filters, mixers, and a mobile app.
Our software implementation is shown above. Because the Tympan library is highly modular, we were able to implement our system in just a few hours. The core of the system is a set of four adaptive filters, each of which reproduces the acoustic channel between one talker and one ear. Each finite-impulse-response filter is updated using the least mean squares algorithm, a classic adaptive filtering algorithm based on stochastic gradient descent. We were able to implement the filters with just a few lines of code using the arm_lms_f32 function from the Arm DSP library. The Tympan had more than enough processing power to run all four filters in real time.
Using controls on the mobile app, the listener can adjust how much the talkers are amplified and how much ambient noise they want to hear. A pair of mixer blocks combine the sound from the earpieces and the adaptive filter outputs. Because the wireless system has negligible delay, the filters are causal, meaning that their outputs are time-aligned with the sound at the ears and the signals can be mixed without distortion. The mobile app also lets us record the inputs and outputs to the Tympan’s memory card for later analysis. We used that feature to produce the demo video below.
The demo uses binaural recordings with a pair of artificial ears; it is best experienced using headphones. First, you will hear the unprocessed sound captured by the earpiece microphones. Because the microphones are in the ears, they have realistic spatial cues. To show how well the system can reduce noise, we set up a fan right next to the ears. Next, you will hear the sound processed by the Tympan’s adaptive filters. The speech should sound the same as it did through the earpiece microphones – with the same spatial cues and the same spectral balance – but without the noise from the fan. Finally, the talkers move to show how the filters adapt to changing conditions.
The Tympan platform made it easy to translate our laboratory system into real embedded hardware. We plan to continue developing this system to improve the performance of the adaptive filters in larger and more dynamic environments. We also want to try the Tympan’s other hardware and software features, such as dynamic range compression, equalization, and behind-the-ear earpieces.