This post describes our paper presented at CAMSAP 2019.
Imagine what it would sound like to listen through someone else’s ears. I don’t mean that in a metaphorical sense. What if you had a headset that would let you listen through microphones in the ears of someone else in the room, so that you can hear what they hear? Better yet, what if your headset was connected to the ears of everyone else in the room? In our group’s latest paper, “Cooperative Audio Source Separation and Enhancement Using Distributed Microphone Arrays and Wearable Devices,” presented this week at CAMSAP 2019, we designed a system to do just that.
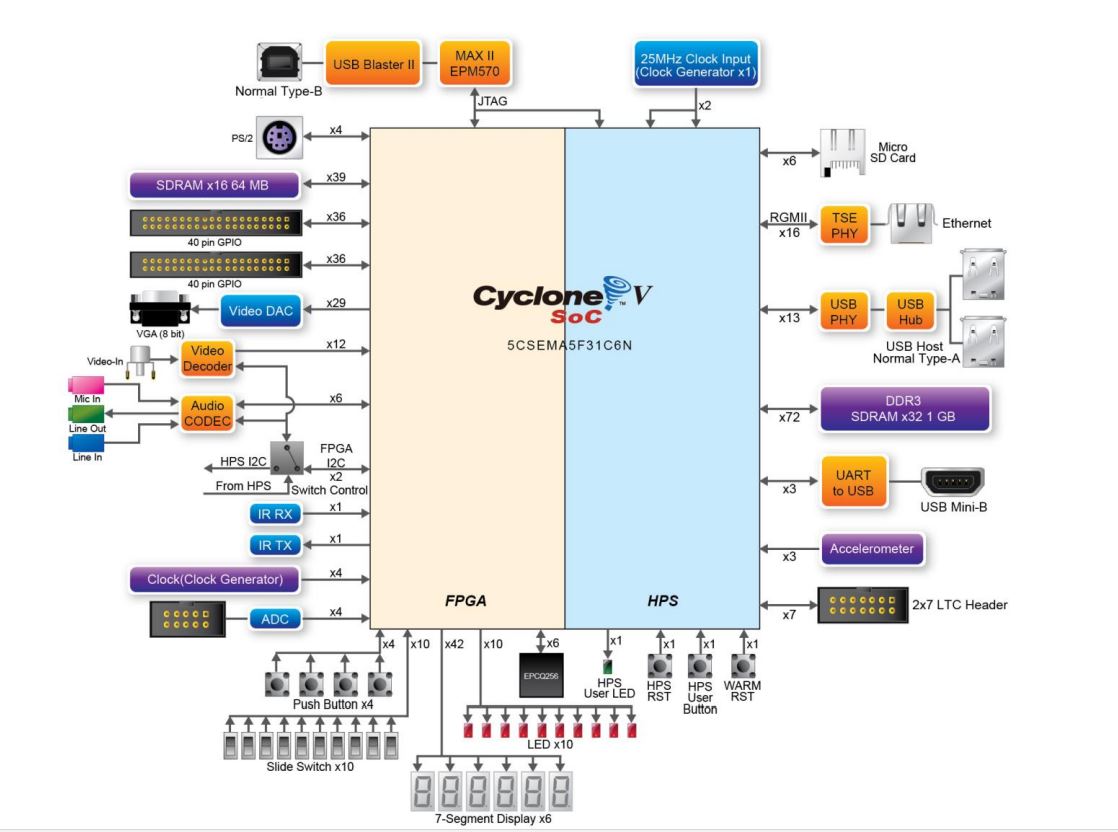
Our team is trying to improve the performance of hearing aids and other augmented listening devices in crowded, noisy environments. In spaces like restaurants and bars where there are many people talking at once, it can be difficult for even normal-hearing people to hold a conversation. Microphone arrays can help by spatially separating sounds, so that each user can hear what they want to hear and turn off the sounds they don’t want to hear. To do that in a very noisy room, however, we need a large number of microphones that cover a large area.
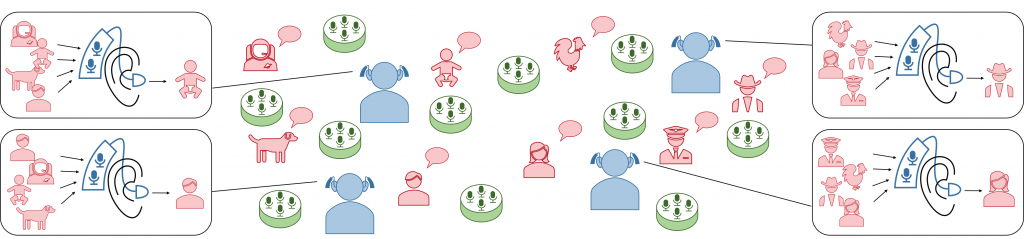
Complex listening environments include many different sound sources, but also many microphone-equipped devices. Each listening device tries to enhance a different sound source.
In the past, we’ve built large wearable microphone arrays with sensors that cover wearable accessories or even the entire body. These arrays can perform much better than conventional earpieces, but they aren’t enough in the most challenging environments. In a large, reverberant room packed with noisy people, we need microphones spread all over the room. Instead of having a compact microphone array surrounded by sound sources, we should have microphones spread around and among the sound sources, helping each listener to distinguish even faraway sounds.