Nearly every modern hearing aid uses an algorithm called dynamic range compression (DRC), which automatically adjusts the amplification of the hearing aid to make quiet sounds louder and loud sounds quieter. Although compression is one of the most important features of hearing aids, it might also be one of the reasons that they work so poorly in noisy environments. Hearing researchers have long known that when DRC is applied to multiple sounds at once, it can cause distortion and make background noise worse. Our research team is applying signal processing theory to understand why compression works poorly in noise and exploring new strategies for controlling loudness in noisy environments.
Although source separation (separating distinct and overlapping sound sources from each other and from dispersed noise) in a small, quiet lab with only a few speakers usually produces excellent results, such a situation may not always be present. In a large reverberant room with many speakers, for example, it may be difficult for a person or speech recognition system to keep track of and to comprehend what one particular speaker is saying. But using source separation in such a scenario to improve intelligibility is quite difficult without having external information that in itself may also be difficult to obtain.
Many source separation methods work well up to only a certain number of speakers – typically not much more than four or five. Moreover, some of these methods rely on constraining the number of microphones to an amount equal to the number of sources, and will scale poorly in terms of results, if at all, with the addition of more microphones. Limiting the number of microphones to the number of speakers will not work in these difficult scenarios, but adding more microphones may help, due to the greater amount of spatial information made available by the additional microphones. Therefore, the motivation behind this experiment was to find a suitable source separation method, or series of such methods, that could leverage the “massive” number of microphones used in the Massive Distributed Microphone Array Dataset and solve the particularly challenging problem of separating ten speech sources. Ideally, the algorithm would rely on as little external information as possible, instead relying on the wealth of information gathered by the microphone arrays distributed around the conference room. Thus, the delay-and-sum beamformer was first considered for this task, because it only requires the locations of each source and microphone, and it inherently scales well with a large number of microphones.
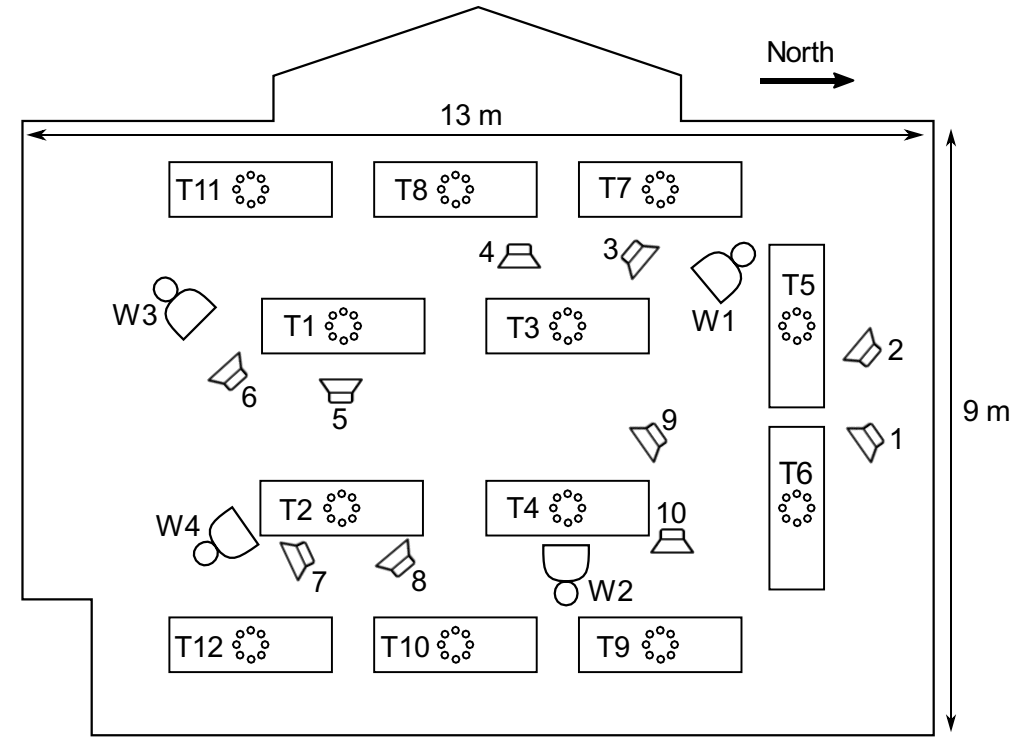
The Dataset
Shown above is a diagram depicting the setup for the Massive Distributed Microphone Array Dataset. Of note is the fact that there are two distinct types of arrays – wearable arrays, denoted by the letter W and numbered from 1-4, and tabletop arrays, denoted by the letter T and numbered from 1-12. Wearable arrays have 16 microphones each, whereas tabletop arrays have 8.
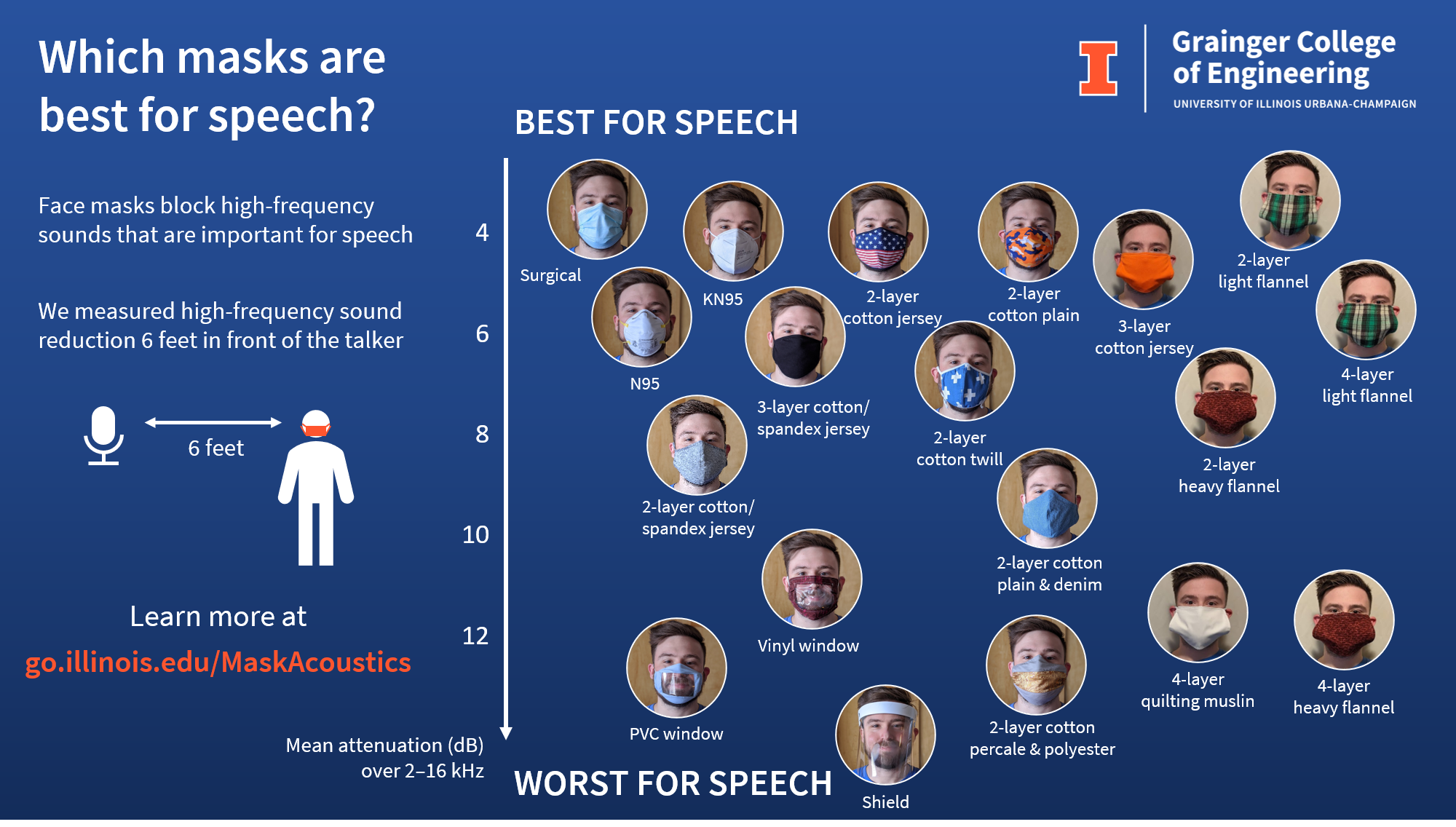
Face masks are a critical tool in slowing the spread of COVID-19, but they also make communication more difficult, especially for people with hearing loss. Face masks muffle high-frequency speech sounds and block visual cues. Masks may be especially frustrating for teachers, who will be expected to wear them while teaching in person this fall. Fortunately, not all masks affect sound in the same way, and some masks are better than others. Our research team measured several face masks in the Illinois Augmented Listening Laboratory to find out which are the best for sound transmission, and to see whether amplification technology can help.
Several months into the pandemic, we now have access to a wide variety of face masks, including disposable medical masks and washable cloth masks in different shapes and fabrics. A recent trend is cloth masks with clear windows, which let listeners see the talker’s lips and facial expressions. In this study, we tested a surgical mask, N95 and KN95 respirators, several types of opaque cloth mask, two cloth masks with clear windows, and a plastic face shield.
We measured the masks in two ways. First, we used a head-shaped loudspeaker designed by recent Industrial Design graduate Uriah Jones to measure sound transmission through the masks. A microphone was placed at head height about six feet away, to simulate a “social-distancing” listener. The loudspeaker was rotated on a turntable to measure the directional effects of the mask. Second, we recorded a human talker wearing each mask, which provides more realistic but less consistent data. The human talker wore extra microphones on his lapel, cheek, forehead, and in front of his mouth to test the effects of masks on sound capture systems.
Our team at the Illinois Augmented Listening Laboratory is developing technologies that we hope will change the way that people hear. But the technology is only one half of the story. If we want our research to make a difference in people’s lives, we have to talk to the people who will use that technology.
Our research group is participating in the National Science Foundation Innovation Corps, a technology translation program designed to get researchers out of the laboratory to talk to real people. By understanding the needs of the people who will benefit from our research, we can make sure we’re studying the right problems and developing technology that will actually be used. We want to hear from:
People with hearing loss who use hearing aids and assistive listening devices
People who don’t use hearing technology but sometimes have trouble hearing
Parents, teachers, school administrators, and others who work with students with hearing loss
Hearing health professionals
People who work in the hearing technology industry
This is not a research study: there are no surveys, tests, or consent forms. We want to have a brief, open-ended conversation about your needs, the technology that you use now, and what you want from future hearing technology.
To schedule a call with our team, please reach out to Ryan Corey (corey1@illinois.edu). Most calls last about 15 minutes and take place over video, though we’re happy to work around your communication needs.
Audio signal processing would seem to have nothing to do with the COVID-19 pandemic. It turns out, however, that a low-complexity signal processing algorithm used in hearing aids can also be used to monitor breathing for patients on certain types of ventilator.
To address the shortage of emergency ventilators caused by the pandemic, this spring the Grainger College of Engineering launched the Illinois RapidVent project to design an emergency ventilator that could be rapidly and inexpensively produced. In little more than a week, the team built a functional pressure-cycled pneumatic ventilator, which is now being manufactured by Belkin.
The Illinois RapidVent is powered by pressurized gas and has no electronic components, making it easy to produce and to use. However, it lacks many of the monitoring features found in advanced commercial ventilators. Without an alarm to indicate malfunctions, clinicians must constantly watch patients to make sure that they are still breathing. More-advanced ventilators also display information about pressure, respiratory rate, and air volume that can inform care decisions.
The Illinois RapidAlarm adds monitoring features to pressure-cycled ventilators.
To complement the ventilator, a team of electrical engineers worked with medical experts to design a sensor and alarm system known as the Illinois RapidAlarm. The device attaches to a pressure-cycled ventilator, such as the Illinois RapidVent, and monitors the breathing cycle. The device includes a pressure sensor, a microcontroller, a buzzer, three buttons, and a display. It shows clinically useful metrics and sounds an audible alarm when the ventilator stops working. The hardware design, firmware code, and documentation are available online with open-source licenses. A paper describing how the system works is available on arXiv.
Microphone arrays are important tools for spatial sound processing. Traditionally, most methods for spatial sound capture can be classified as either beamforming, which tries to isolate a sound coming from a single direction, or source separation, which tries to split a recording of several sounds into its component parts. Beamforming and source separation are useful in crowded, noisy environments with many sound sources, and are widely used in speech recognition systems and teleconferencing systems.
Since microphone arrays are so useful in noisy environments, we would expect them to work well in hearing aids and other augmented listening applications. Researchers have been building microphone-array hearing aids for more than 30 years, and laboratory experiments have consistently shown that they can reduce noise and improve intelligibility, but there has never been a commercially successful listening device with a powerful microphone array. Why not?
The problem may be that most researchers have approached listening devices as if they were speech recognition or teleconferencing systems, designing beamformers that try to isolate a single sound and remove all the others. They promise to let the listener hear the person across from them in a crowded restaurant and silence everyone else. But unlike computers, humans are used to hearing multiple sounds at once, and our brains can do a good job separating sound sources on their own. Imagine seeing everyone’s lips move but not hearing any sound! If a listening device tries to focus on only one sound, it can seem unnatural to the listener and introduce distortion that makes it harder, not easier, to hear.
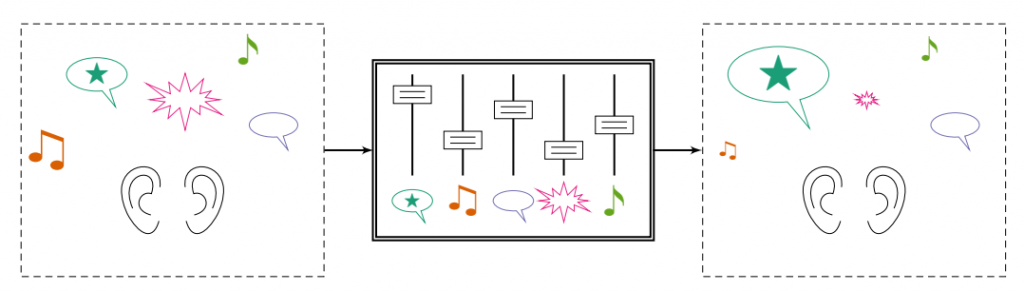
A source remixing system changes the relative levels of sounds in a mixture while preserving their spatial cues.
This paper proposes a new type of array processing for listening devices: source remixing. Instead of trying to isolate or separate sound sources, the system tries to change their relative levels in a way that sounds natural to the listener. In a good remixing system, it will seem as if real-world sounds are louder or quieter than before.
When our team designs wearable microphone arrays, we usually test them on our beloved mannequin test subject, Mike A. Ray. With Mike’s help, we’ve shown that large wearable microphone arrays can perform much better than conventional earpieces and headsets for augmented listening applications, such as noise reduction in hearing aids. Mannequin experiments are useful because, unlike a human, Mike doesn’t need to be paid, doesn’t need to sign any paperwork, and doesn’t mind having things duct-taped to his head. There is one major difference between mannequin and human subjects, however: humans move. In our recent paper at WASPAA 2019, which won a best student paper award, we described the effects of this motion on microphone arrays and proposed several ways to address it.
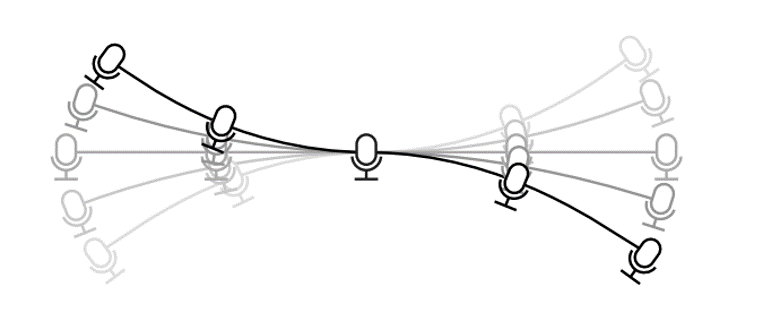
Beamformers, which use spatial information to separate and enhance sounds from different directions, rely on precise distances between microphones. (We don’t actually measure those distances directly; we measure relative time delays between signals at the different microphones, which depend on distances.) When a human user turns their head – as humans do constantly and subconsciously while listening – the microphones near the ears move relative to the microphones on the lower body. The distances between microphones therefore change frequently.
In a deformable microphone array, microphones can move relative to each other.
Microphone array researchers have studied motion before, but it is usually the sound source that moves relative to the entire array. For example, a talker might walk around the room. That problem, while challenging, is easier to deal with: we just need to track the direction of the user. Deformation of the array itself – that is, relative motion between microphones – is more difficult because there are more moving parts and the changing shape of the array has complicated effects on the signals. In this paper, we mathematically analyzed the effects of deformation on beamformer performance and considered several ways to compensate for it.
The EchoXL is a large format Alexa-powered smart speaker as part of TEC’s Alexa program. Based on the current market offerings, it would be the largest of its kind. It’s form and features will be modeled after Amazon’s Echo speaker, to keep branding consistent and to also exemplify a potential line expansion. While small Bluetooth speakers still hold the largest market segment in audio, the market for larger sound systems has been steadily increasing over the past few years (as evidenced by new products from LG, Samsung, Sony, and JBL). Currently, Amazon does not have any products in this category.
The speaker will be used as a public demonstration piece to exhibit the current technology incorporated within smart speakers, such as the implementation of microphone arrays as wells as internal room correction capabilities. The novelty factor of a scaled up Echo speaker will also be useful for press for the group’s research.