
This post describes our paper “Motion-Robust Beamforming for Deformable Microphone Arrays,” which won the best student paper award at WASPAA 2019.
When our team designs wearable microphone arrays, we usually test them on our beloved mannequin test subject, Mike A. Ray. With Mike’s help, we’ve shown that large wearable microphone arrays can perform much better than conventional earpieces and headsets for augmented listening applications, such as noise reduction in hearing aids. Mannequin experiments are useful because, unlike a human, Mike doesn’t need to be paid, doesn’t need to sign any paperwork, and doesn’t mind having things duct-taped to his head. There is one major difference between mannequin and human subjects, however: humans move. In our recent paper at WASPAA 2019, which won a best student paper award, we described the effects of this motion on microphone arrays and proposed several ways to address it.
Beamformers, which use spatial information to separate and enhance sounds from different directions, rely on precise distances between microphones. (We don’t actually measure those distances directly; we measure relative time delays between signals at the different microphones, which depend on distances.) When a human user turns their head – as humans do constantly and subconsciously while listening – the microphones near the ears move relative to the microphones on the lower body. The distances between microphones therefore change frequently.
In a deformable microphone array, microphones can move relative to each other.
Microphone array researchers have studied motion before, but it is usually the sound source that moves relative to the entire array. For example, a talker might walk around the room. That problem, while challenging, is easier to deal with: we just need to track the direction of the user. Deformation of the array itself – that is, relative motion between microphones – is more difficult because there are more moving parts and the changing shape of the array has complicated effects on the signals. In this paper, we mathematically analyzed the effects of deformation on beamformer performance and considered several ways to compensate for it.
Effects of deformation
Modeling the effects of motion requires some fairly advanced math, but the result is simple and intuitive. When the scale of the motion between two microphones is much smaller than a wavelength of sound, it doesn’t have much effect on the signals and we can safely ignore it. When the motion is much larger than a wavelength of sound, it will essentially destroy the information provided by the array and make it useless for standard beamforming techniques. If the range of motion is comparable to a wavelength, then we still get some information but we have to use it carefully.
Sound wavelengths correspond to frequencies: the lowest frequency in human speech is about 100 Hz, which has a wavelength of about 10 ft; small body movements are not a problem at these frequencies. The highest frequencies we can hear have wavelengths less than 1 inch. It is these high frequencies for which motion is most harmful. In our experiments, we compared the performance of a wearable microphone array on a human and mannequin. Low-frequency performance is the same, but high-frequency performance is dramatically worse for the human, even when he is trying to stand perfectly still; just the subtle motion due to breathing is harmful!
Dealing with motion

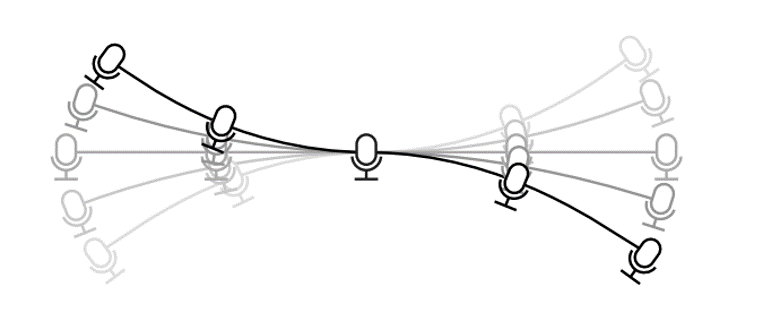
Different strategies for beamforming with moving or deformable microphone arrays. Performance depends on the amount of motion.
The graphic above shows four approaches to compensating for motion. (Because my animation skills are not the best, the graphic technically shows a rigidly moving array rather than truly deformable one, but the principle is the same.) If the motion is very small, as in the top left panel, we can use an ordinary beamformer without modification. That is, we can just ignore the motion. If the microphones move too much, though, the beam will sometimes point away from the target source.
If the motion is too large to ignore but still fairly small, then we can “widen” the beam, as shown in the upper right panel. The math is a little bit more complicated than just making it wider – we’re really averaging over the different states the microphones could be in – but the principle is the same. This modified beamformer is more robust to deformation, but it also doesn’t reduce noise as much as the narrow beamformer would. The wide beamformer is appealing because it’s simple to implement and, crucially, it doesn’t change over time. The processing is the same no matter where the microphones are.
If the motion is so large that a single beam can’t separate the target source from unwanted interference sources in all states of motion, then we can’t use the simple time-invariant beamformer. Instead, we must explicitly track the motion of the microphones and change the beamformer as they move, as shown in the lower left of the figure above. This strategy, while potentially the most effective, is more difficult to implement: we have to model how the microphones move, track them, and adapt our processing over time without introducing distortion.
The fourth case, shown on the lower right, is the most interesting: the deformable microphone array is actually a set of several individual devices connected together. Each device is rigid and moves only slightly, so that the microphones within a device don’t move relative to each other, but microphones from different devices do. We proposed an algorithm for this system in a previous paper at IWAENC 2018. Each device does beamforming on its own, but the devices share information about which sources are producing sound at which times and frequencies. Although it was developed for devices that have slightly different sample rates, it also works for motion; both relative motion and sample rate offsets stretch or squeeze signals in time, so they’re mathematically similar.
Experiments

In one experiment, microphones were hung from a rotating pole while loudspeakers around them played speech samples.
The best way to deal with motion, if we can, is to explicitly track the position of each microphone as it moves. In the real world that would be very difficult, but we can do it in the laboratory. In our first experiment, we attached 12 microphones to a pole that we swung back and forth. The microphones swung freely on cables, but generally moved along a fixed path. To track the positions of the microphones over time, we set up three loudspeakers that played special ultrasonic test signals. The beamformer could lock onto these inaudible pilot signals to learn its position. By tracking motion, the beamformer did nearly as well with the moving array as it did with a nonmoving array.
Next, we considered human motion with a twelve-microphone wearable array. The ultrasonic tracking system worked so well for the pole, we thought it would work well for a human as well. It did not. Even relatively simple motion such as nodding was too inconsistent to track reliably. However, we were able to apply the “widened” motion-robust beamformer. As expected, it improved performance for small motion, such as breathing and slight gesturing, especially at moderate frequencies, but was little help at high frequencies for larger motion such as dancing.
The results of these experiments would seem pessimistic: to get good performance, we need large arrays, but large arrays don’t work well in the real world due to motion. There is some good news, however: motion is only harmful at high frequencies, and small arrays work just fine at high frequencies. We need larger arrays to help with low frequencies, which are not as sensitive to motion. Thus, the best approach might be a hybrid system made up of small, rigid arrays connected together. Each small rigid array will work well at high frequencies, while the overall deformable array will work well at low frequencies. If the pieces are far apart – say, spread around the room – we need to use a special distributed algorithm like the one we proposed at IWAENC. But if they on different parts of a user’s body, a motion-robust beamformer will work just fine.
The video below, which is best experienced using stereo headphones, demonstrates the performance of a wearable array with several microphones on a rigid cap and several spread around the moving torso and arms. The beamformer performs remarkably well despite the motion. More sound examples are available on our demos page.
This paper showed that microphone motion is a difficult problem, but not an impossible one. It is also a critical roadblock to realizing powerful wearable microphone arrays that will dramatically improve the performance of hearing aids and other augmented listening systems. It will likely take years of effort by many research teams to develop algorithms and that can deal with the full range of human motion with body-scale arrays. We hope that this paper will inspire others to tackle this problem.
If you are interested in working on this problem, please get in touch! We’d love to hear from you.