
This post describes our paper “Binaural Audio Source Remixing for Microphone Array Listening Devices” presented at ICASSP 2020. You can read the paper here or watch the video presentation here.
Microphone arrays are important tools for spatial sound processing. Traditionally, most methods for spatial sound capture can be classified as either beamforming, which tries to isolate a sound coming from a single direction, or source separation, which tries to split a recording of several sounds into its component parts. Beamforming and source separation are useful in crowded, noisy environments with many sound sources, and are widely used in speech recognition systems and teleconferencing systems.
Since microphone arrays are so useful in noisy environments, we would expect them to work well in hearing aids and other augmented listening applications. Researchers have been building microphone-array hearing aids for more than 30 years, and laboratory experiments have consistently shown that they can reduce noise and improve intelligibility, but there has never been a commercially successful listening device with a powerful microphone array. Why not?
The problem may be that most researchers have approached listening devices as if they were speech recognition or teleconferencing systems, designing beamformers that try to isolate a single sound and remove all the others. They promise to let the listener hear the person across from them in a crowded restaurant and silence everyone else. But unlike computers, humans are used to hearing multiple sounds at once, and our brains can do a good job separating sound sources on their own. Imagine seeing everyone’s lips move but not hearing any sound! If a listening device tries to focus on only one sound, it can seem unnatural to the listener and introduce distortion that makes it harder, not easier, to hear.
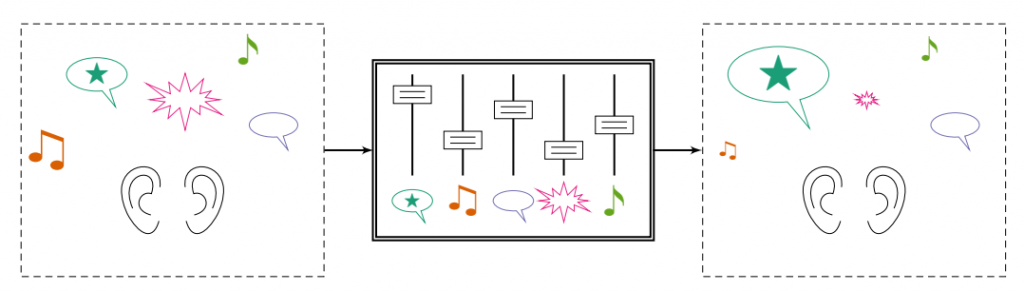
A source remixing system changes the relative levels of sounds in a mixture while preserving their spatial cues.
This paper proposes a new type of array processing for listening devices: source remixing. Instead of trying to isolate or separate sound sources, the system tries to change their relative levels in a way that sounds natural to the listener. In a good remixing system, it will seem as if real-world sounds are louder or quieter than before.
Consider a mixing board in a movie studio. The artist has recordings of each actor’s dialogue and each sound effect and music track, and each of those tracks has its own slider on the mixing board. The artist carefully adjusts the level of each sound so that the audience can understand the dialogue while still enjoying the immersion of the sound effects and music.
Imagine if a listening device could do that same careful mixing, but for real-life sounds. In a very challenging environment, like a crowded bar, it would reduce background noise as much as possible, like a conventional beamformer. In easy listening environments, like a quiet living room, it would do no processing at all and let the brain do the work. In most situations, the sound levels should be set somewhere in between, with background sounds reduced just enough to help the listener understand what they need to.
Remixing and distortion
New clinical research is required to understand how best to set the sound levels in a remixing system, but in the meantime, we can analyze the math behind source remixing. In this paper, we propose a source-remixing system for microphone array listening devices. Using both math and experiments, we show how the relative level of each source in the mixture affects the performance of the system. The more the system tries to separate the sources, the more difficult it is and the more distortion we introduce.
The paper focuses on two types of distortion: spectral and spatial.
Spectral distortion: Even if we have a large, powerful microphone array, it is impossible to perfectly isolate a single sound source. Some of the other signals will always leak into the output, and when they do, they’ll be distorted. They might sound tinny or muffled or reverberant, for example. This distortion can get in the way of the brain’s natural source separation process, ultimately doing more harm than good. If the processing system is designed to preserve a fraction of the other signals, however, that distortion will be less severe. Remixing is an easier problem than complete separation.
Spatial distortion: Humans localize sounds in space by comparing the signals at the left and right ears. A signal from the right will reach the right ear first and will be louder in the right ear than in the left ear. An augmented listening device produces two outputs, one for the left ear and one for the right ear, and it needs to make sure that the relative times and levels of those signals are correct. If the system is designed to isolate a single sound source, it can do that fairly easily: it just matches the spatial cues of the target. However, any other sound sources that are not perfectly removed will sound like they are coming from the same direction. If a beamformer is pointed to a talker on the left and car horn comes from the right, the car will sound like it’s on the left. The brain can no longer tell which sounds are coming from which direction, which can be disorienting and dangerous. A remixing system, however, can preserve those spatial cues.
The paper shows, both mathematically and experimentally, that choosing more similar target levels in the mixture reduces both spectral and spatial distortion. A single-target beamformer produces the most distortion, while applying the same processing to all sources causes no distortion at all. Performance also depends on how easy the signals are to separate: with a large microphone array and sound sources that are far from each other, we can achieve low distortion even for complete separation, but with only a few microphones and closely spaced sources, the levels cannot be too far apart.
Other benefits of remixing
This paper focused on spectral and spatial distortion, but we hypothesize that there are other benefits of remixing compared to complete separation:
- Delay: listening devices have severe delay constraints. A remixing system should require less delay to achieve the same level of performance compared to a separation system.
- Sensitivity: spatial processing systems rely on estimates of source locations and room acoustics. Errors in these estimates can degrade performance. A remixing system should be less sensitive to errors in these acoustic parameters.
- Artifacts: Nonlinear speech separation and enhancement systems, such as time-frequency masks, can introduce artifacts that are sometimes called musical noise. Remixing systems should be less susceptible to these artifacts because they vary less over time.
We hope to explore these other benefits of remixing in future work.
While beamforming and source separation are appropriate in some applications, we need a different approach for human listeners. Source remixing is a useful framework for enhancing human hearing in a perceptually transparent way.