Final Report
The final report for this project, submitted to the Andrew W. Mellon Foundation, is available here.
Publications & Presentations
The full list of publications and presentations from this project is available on the Publications & Presentations page.
Summary
This project identified four key research questions, as well as six main deliverables. In brief, these are the following:
- What are the challenges and differences for converting legacy special collections metadata records to linked open data?
- How can LOD help better integrate special collections interfaces into library services?
- Can LOD better identify external resources that might provide context and enriched item descriptions for special collections?
- How can LOD be leveraged to visualize special collections data in a new way that isn’t bibliocentric?
On these topics, we identified and share the following deliverables:
Motley and Portraits of Actors: Experimental LOD-Enriched Interfacehttp://imagesearch-test1.library.illinois.edu/cdm/Example Item Link:http://imagesearch-test1.library.illinois.edu/cdm/ref/collection/motley-new/id/151Each of the collections can be browsed from the Collection homepage (reached by clicking on collection title) or from any item page by clicking on Browse All (in header). From there, browsing can be limited by performance or (for Motley only) by theater. In limited browse a knowledge card about the performance (or theater) appears in the upper right with the list of results for that performance or theater. Individual item views display information about entities mentioned in the item’s metadata on the left hand side. This is an unstable, experimental, test interface subject to change, bugs and occasional outages. Still in active development and under consideration for production.
Kolb-Proust Archive for Research: LOD-enriched (person entities) interfacehttp://kolbproust.library.illinois.edu/proust/searchExample Result Link:http://kolbproust.library.illinois.edu/proust/search?keyword=comtesseTEI serialization of Kolb’s notecards were enriched with links to RDF descriptions of <Persons> mentioned on each card and re-serialized as RDF (JSON-LD) using schema.org semantics and ingested into local Virtuoso server. From the Example Result Link given above, hover over the names included on the display of the first notecard (right side of display, grey background). Tool tips will provide additional information about the individuals, i.e., preferred form of name, birth and death years, and in some cases gender and link to more information in VIAF or Wikipedia (English and/or French).
Interface for exploring connections co-occurrence of families of individuals that are mentioned in Professor Kolb’s notecards. Each graph is centered on a family, and shows the first-degree (and optionally) second-degree connections with other families in the network. Each family is represented by a dot which is bigger or smaller based on the number of members of the family. Connections are shown based on a member of one family being mentioned on the same card as a member of another family. Thicker lines of connections indicate more connections between two families. A date range slider at the bottom can be used to explore connections between families between a narrower range of dates, and the graph can be told to center on a different family. Local (to Web browser on client) annotations can be added to nodes in the form of text notes or links. This interface is an early (alpha) level experiment, not in production. Outlook as of now for further development is uncertain.
Each Motley/Portraits item page is displayed from the server with a JSON-LD serialized RDF description of the item included and script references to either motley.js or poa.js. These JavaScripts parse the included JSON-LD and call Wikipedia, DBPedia and/or VIAF as appropriate to generate the more-information boxes for entities (people, theaters, performances) associated with the item (and displayed on the left-hand side of the item display. The JavaScript file harvests data and links about entities in real time using the Wikipedia and VIAF links stored in the JSON file, and displays the results on the left side of the Web page, making use of mustache templates. Also included in this portion of our project software repository is item.php (the server-side php script that generates the initial item- level html response page which is then enriched by motley.js or poa.js), as well as the browsing html templates (item 2 above) and associated JavaScripts.
XSL with an embedded JavaScript function for generating tooltips with basic biographical information and related links when the cursor hovers over a linked name in a card (see item 3 above). Calls a function that queries a triple store (local instance of Virtuoso) to get the data to display.
JavaScripts and CSS stylesheets used to generate graph view of family co-occurrences (depends on D3 JavaScript library for data-driven documents). Also included in this repository are the JSON serializations of co-occurrence data used to generate graphs (distilled from notecard and Person RDF).
Python script for combining a number of spreadsheet sources to generate a JSON-LD file for each item in the Motley Theater Collection. Creates Solr ‘documents’ JSON records at same time. Recent example of CSV version of spreadsheets with enriched and reconciled metadata is included.https://github.com/CIRSS/lod-project/tree/master/theater-collections/backend/portraits-of-actorsScript for combining a spreadsheet source to generate a JSON-LD file for each item in the Portraits of Actors Collection. Creates Solr ‘documents’ JSON records at same time. Recent example of CSV version of spreadsheets with enriched and reconciled metadata is included.
Python scripts for transforming the Kolb-Proust data. ConvertTEI2JSON.py converts each of the legacy TEI cards into a JSON file in the same directory as the original TEI file. The transformation is only partial, with the focus being on storing the metadata in the JSON files, but leaving the full text in the TEIs.https://github.com/CIRSS/lod-project/tree/master/kolb-proust/add-journal-linksScript for adding links to the 10 most frequently cited newspapers to the TEI files.
This repository contains Python scripts used to query VIAF Auto Suggest API to reconcile (find VIAF URLs for) names encountered in Motely, Portraits and KPA legacy metadata. This tool pre-existed this project, but updates were made in improve these scripts for use in our project.
New Item Record Mockups
Wireframes of new item record interfaces were drafted in project year 1 to incorporate RDFa and new linked data that will be added to item metadata. The interface is key to the incorporation of linked open data, and its utilization by users. Each record will have a dynamically generated left hand column with linked data pulled into the item record from DBpedia, VIAF, the Library of Congress and other sources. The information under the item will be generated from metadata stored in CONTENTdm. Here are the full mockups (click each photo for full resolution):
-

- Main wireframe of new item record.
-

- Left hand column will be LOD pulled from RDF in item record.

-

- Section below item is generated from item metadata, stored locally.

-
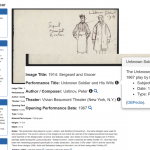
- This section includes buttons that generate pop-ups with more information about particular pieces of metadata.
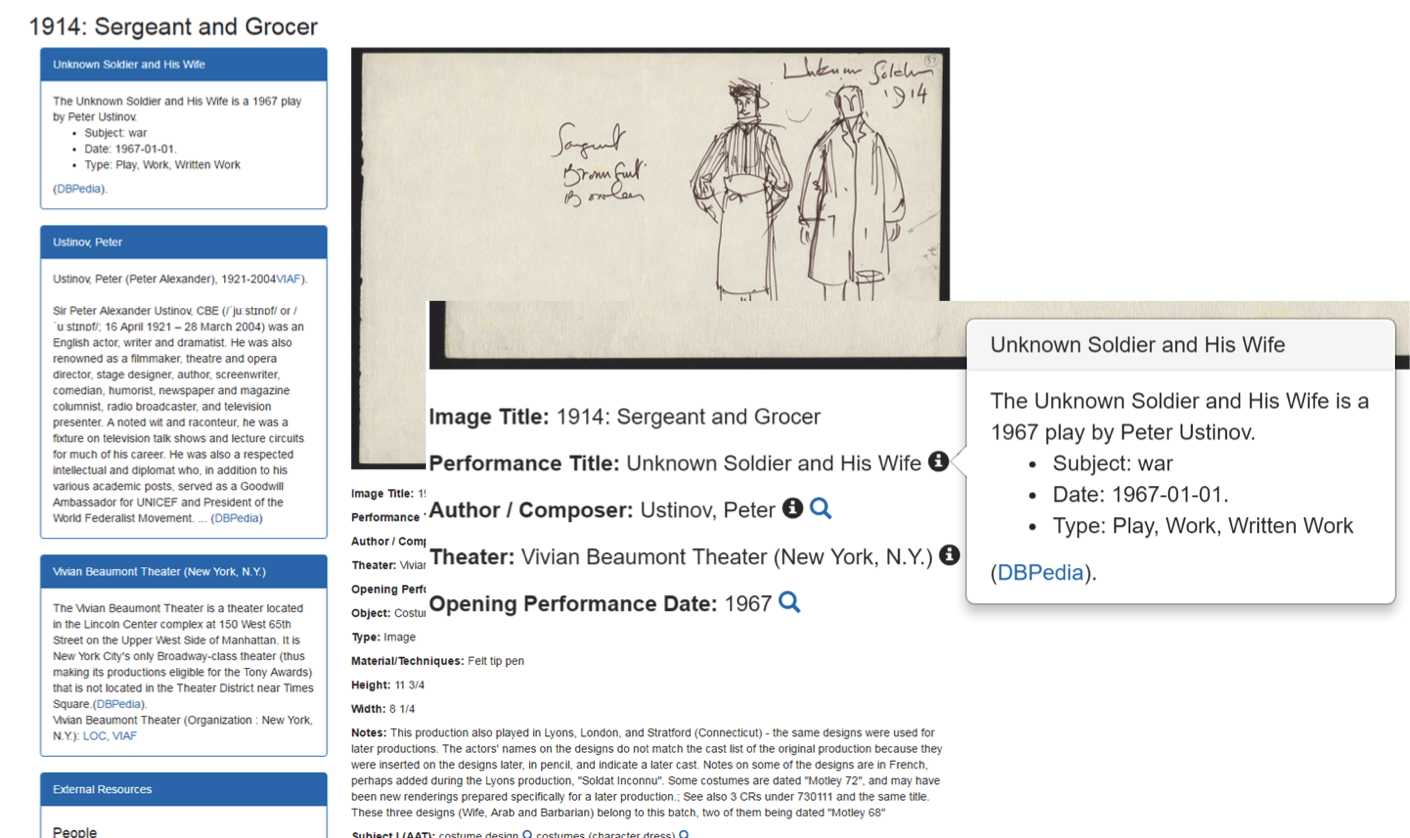
-
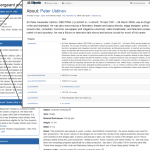
- Preview of full information available at external source, here DBPedia.

White Papers
Two white papers were drafted covering the work, challenges and lessons learned on the project.
White paper #1, titled “Transforming Special Collections Metadata into Linked Open Data: Mappings, entity reconciliation, workflows implemented & lessons learned,” and predictably covers the metadata transformation process, is available both on the project website and in IDEALS.
White paper #2, titled “Analysis of Early User Feedback,” discusses early user testing efforts of the enhanced collection interfaces and records, and is also available on this site and in IDEALS.