Introduction
As new technology has revolutionized the ways all fields gather information, scholars have integrated the use of digital software to enhance traditional models of research. While digital software may seem only relevant in scientific research, digital projects play a crucial role in disciplines not traditionally associated with computer science. One of the biggest digital initiatives actually takes place in fields such as English, History, Philosophy, and more in what is known as the digital humanities. The digital humanities are an innovative way to incorporate digital data and computer science within the confines of humanities-based research. Although some aspects of the digital humanities are exclusive to specific fields, most digital humanities projects are interdisciplinary in nature. Below are three general impacts that projects within the digital humanities have enhanced the approaches to humanities research for scholars in these fields.
Digital Access to Resources
Digital access is a way of taking items necessary for humanities research and creating a system where users can easily access these resources. This work involves digitizing physical items and formatting them to store them on a database that permits access to its contents. Since some of these databases may hold thousands or millions of items, digital humanists also work to find ways so that users may locate these specific items quickly and easily. Thus, digital access requires both the digitization of physical items and their storage on a database as well as creating a path for scholars to find them for research purposes.
Providing Tools to Enhance Interpretation of Data and Sources
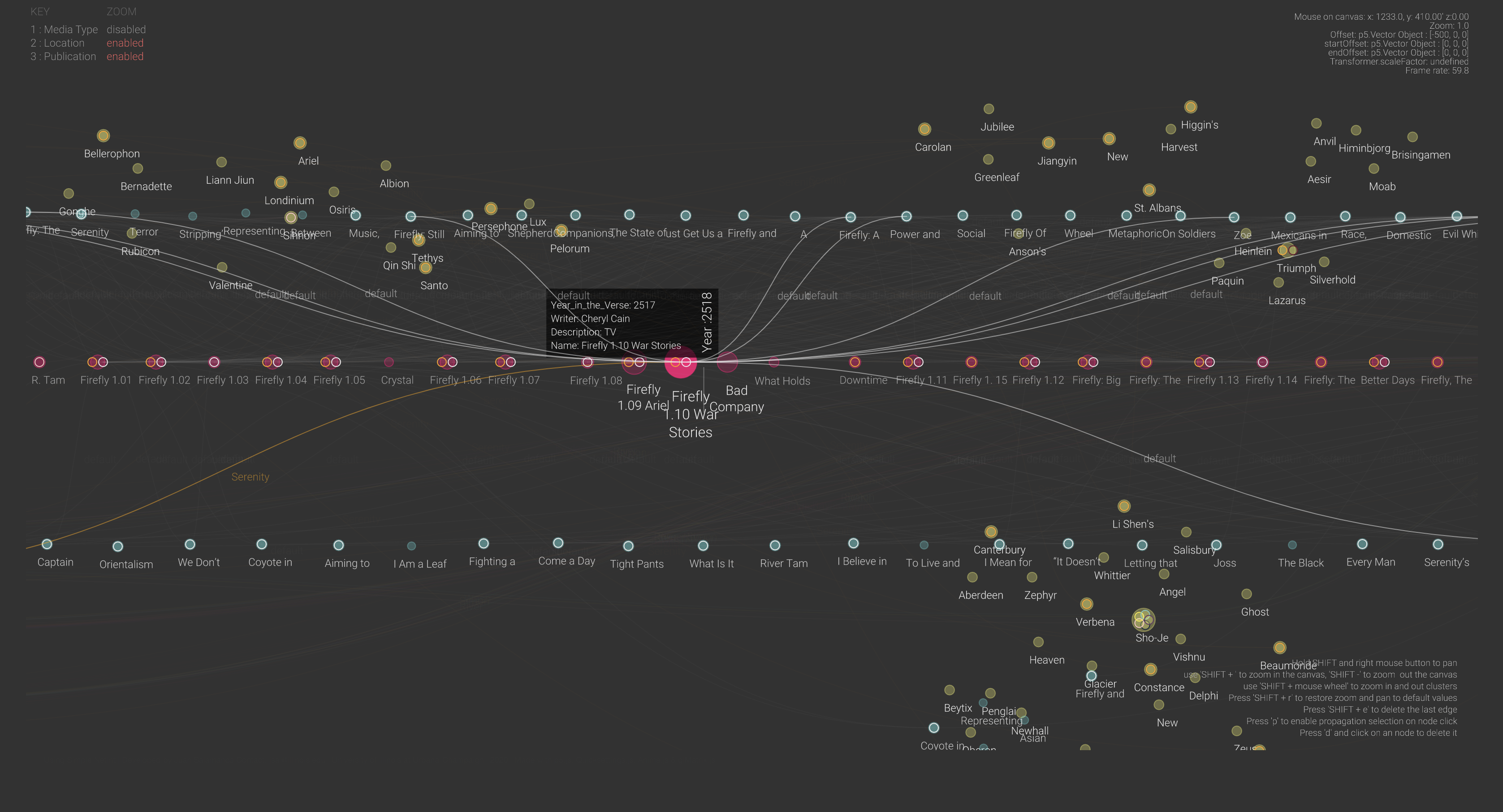
The digital humanities can also change how we can interpret sources and other items used in the digital humanities. Data Visualization software, for example, helps simplify large, complex datasets and presents this data in ways more visually appealing. Likewise, text mining software uncovers trends through analyzing text that potentially saves hours or even days for digital humanists had they analyzed the text through analog methods. Finally, Geographic Information Systems (GIS) software allows for users working on humanities projects to create special types of maps that can both assist in visualizing and analyzing data. These software programs and more have dramatically transformed the ways digital humanists interpret and visualize their research.
Digital Publishing
The digital humanities have opened new opportunities for scholars to publish their work. In some cases, digital publishing is simply digitizing an article or item in print to expand the reach of a given publication to readers who may not have direct access to the physical version. Other times, some digital publishing initiatives publish research that is only accessible in a digital format. One benefit to digital publishing is that it opens more opportunities for scholars to publish their research and expands the audience for their research than just publishing in print. As a result, the digital humanities provide scholars more opportunities to publish their research while also expanding the reach of their publications.
How Can I Learn More About the Digital Humanities?
There are many ways to get involved both at the University of Illinois as well as around the globe. Here is just a list of a few examples that can help you get started on your own digital humanities project:
- HathiTrust is a partnership through the Big Ten Academic Alliance that holds over 17 million items in its collection.
- Internet Archive is a public, multimedia database that allows for open access to a wide range of materials.
- The Scholarly Commons page on the digital humanities offers many of the tools used for data visualization, text mining, GIS software, and other resources that enhance analysis within a humanities project. There are also a couple of upcoming Savvy Researcher workshops that will go over how to use software used in the digital humanities
- Sourcelab is an initiative through the History Department that works to publish and preserve digital history projects. Many other humanities fields have equivalents to Sourcelab that serves the specific needs of a given discipline.