
While data analysis has existed in one form or another for centuries, its modern concept is highly tied to a digital environment, which means that people who are looking to move into the data science field will undoubtedly need some technology skills. In the data field, the primary coding languages include Python, R, and SQL. Software is a bit more complicated, with numerous different programs and services used depending on the situation, including Power BI, Spark, SAS, Excel, to name a few. While this is overwhelming, remember that it is not important to become an expert in all of the languages and software. Becoming skilled in one language and a few of the software options, depending on your interest or on the in-demand skills on job listings, will give you the transferable skills to quickly pick up the other languages and software as needed. If this still seems to be an overwhelming prospect, remember that the best way to eat an elephant is one bite at a time. Take your time, break up the task, and focus on one step at a time!
LinkedIn Learning
- Python for Data Science Essential Training Part 1
- This 6 hour course guides users through an entire data science project that includes web scrapers, data cleaning and reformatting, generate visualizations, preform simple data analysis and create interactive graphs. The project will have users coding in Python with confidence and give learners a foundation in the Plotly library. Once completed, learners will be able to design and run their own data science projects.
- R for Excel Users
- With Excel being a familiar platform for many interested in data, it is an ideal bridge to more technical skills, like coding in the R language. This course is specifically designed for data analytics with its focus on statistical tasks and operations. It will take user’s Excel skills to another level while also laying a solid foundation for their new R skills. Users will be able to switch between Excel and the R Desctools package to complete tasks seamlessly, using the best of each software to calculate descriptive statistics, run bivariate analyses, and more. This course is for people who are truly proficient in Excel but new to R, so if you need to brush up your Excel skills, go back to the first post in this series and go over the Excel resources!
- SQL Essential Training
- SQL is the language of relational databases, so it is of interest to anyone looking to expand their data handling skills. This training is designed to give data wranglers the tools they need to use SQL effectively using the SQLiteStudio Software. Learners will soon be able to create tables, define relationships, manipulate strings, use triggers to automate actions, and use sub selects and views. Real world examples are used throughout the course and learners will finish the course by building their own SQL application. If you want a gentler introduction to SQL, check out our earlier post on SQL Murder Mystery
O’Reilly Books and Videos (Make sure to follow these instructions for logging in!)
- Data Analysts Toolbox – Excel, Python, Power BI, Alteryx, Qlik Sense, R, Tableau
- This 46 hour course is not for the faint of heart, but by the end, users will be a Swiss army knife data analyst. This isn’t for true beginners, but rather people who are already familiar with the basic data analysis concepts and have a good grasp of Excel. It is included in this list because it is a great source for learning the basics of the myriad of software and programming languages that data analysts are expected to know, all in one place. The course starts with teaching users about advanced pivot tables, so if users have already mastered the basic pivot table, they should be ready for this course.
- Programming for Data Science: Beginner to Intermediate
- This is an expert curated playlist of courses and book chapters that is designed to help people who are familiar with the math side of data analysis, but not the computer science side. This playlist gives users an introduction to NumPy, Pandas, Python, Spark and other technical data skills. Some previous experience with coding may be helpful in this course, but patience will make up for lack of experience.
In the Catalog
- Python crash course : a hands-on, project-based introduction to programming
- Python is often lauded as one of the most approachable coding languages to learn and its functionality makes it popular in the data science field. So it is no surprise that there are a lot of resources on and off campus for learning Python. This approachable guide is just one of the many resources available to UIUC students, but it stands out with its contents and overall outcomes. “Python Crash Course” covers general programming concepts, Python fundamentals, and problem solving. Unlike some other resources, this guide focuses on many of Python’s uses, not just its data analytics capabilities, which can be appealing to people who want to be more versatile with their skills. However, it is the three projects that make this resource stand out from the rest. Readers will be guided in how to create a simple video game, use data visualization techniques to make graphs and charts, and build an interactive web application.
- The Book of R : a first course in programming and statistics
- R is the most popular coding language for statistical analysis, so it’s clearly important for data analysts to learn. The Book of R is a comprehensive and beginner friendly guide designed for readers who have no previous programming experience or a shaky mathematical foundation as readers will learn both concurrently through the book’s lessons. Starting with writing simple programs and data handling skills, learners will then move forward to producing statistical summaries of data, preforming statistical tests and modeling, create visualizations with contributed packages like ggplot2 and ggvis, write data frames, create functions, and use variables, statements, and loops; statistical concepts like exploratory data analysis, probabilities, hypothesis tests, and regression modeling, and how to execute them in R; how to access R’s thousands of functions, libraries, and data sets; how to draw valid and useful conclusions from your data; and how to create publication-quality graphics of your results.
Join us next week for our final installment of the Winter Break Data Analysis series: “You can’t analyze data if you ain’t cute: Data Visualization for Data Analysis”

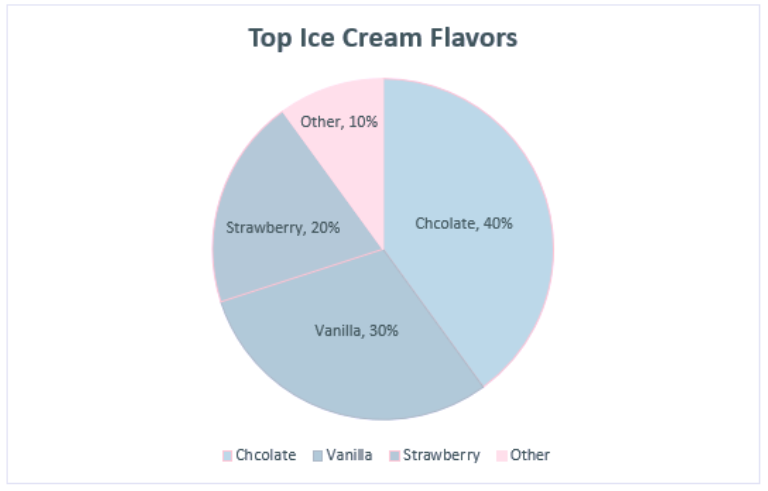
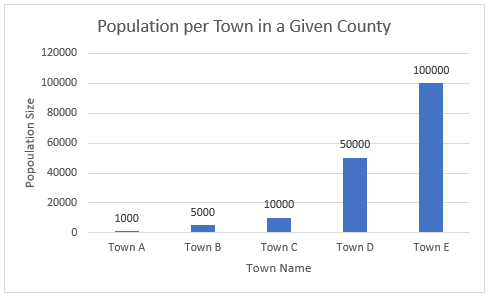
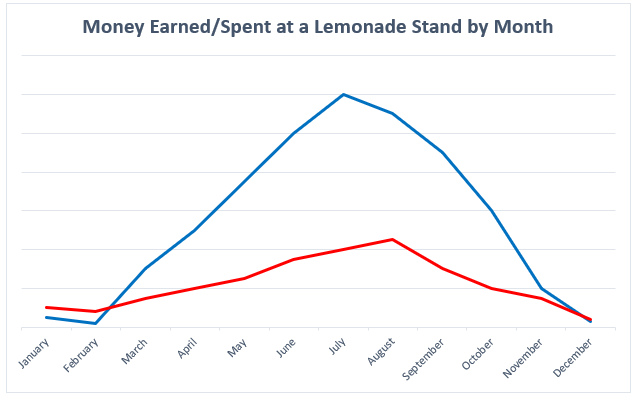
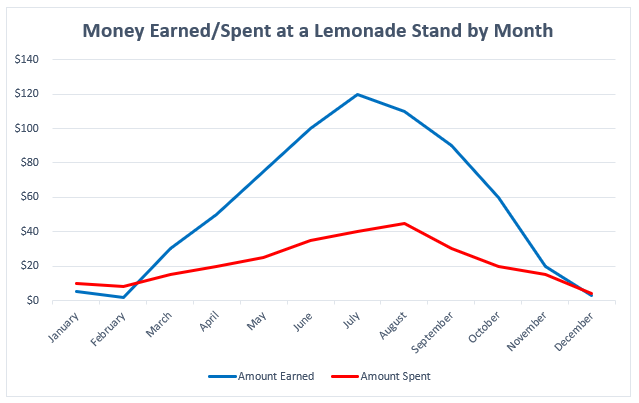

 Lauren Phegley is a graduate assistant for the Library Research Data Service pursuing her Masters of Science in Library and Information Science at the University of Illinois iSchool. Once she graduates in May 2022, she hopes to work as an academic librarian helping researchers manage their data and research.
Lauren Phegley is a graduate assistant for the Library Research Data Service pursuing her Masters of Science in Library and Information Science at the University of Illinois iSchool. Once she graduates in May 2022, she hopes to work as an academic librarian helping researchers manage their data and research.