Research
Introduction
On the Web, information about a single real-world entity, such as a restaurant or a person, is usually spread across many different Web sites. Current search engines such as Google and Bing organize the information in terms of keywords and documents. When people search information about some entities, the search engines return web pages based on query keywords occurrences alone, without a deeper understanding of the entity information. This puts the burden on users to formulate the right queries, to identify the correct search results, and to read and glean the insights by reading multiple pages. Our research vision is to take search beyond pages. We expect to discover information about real-world entities automatically from the massive and heterogeneous Web, then organize it as a more structured view of the entities by careful integration. This leads to our ARISE search service, which aims to provide mobile and other Web-based applications access to entity-oriented information in an organized way.
Navigating Web Information on the Real World
The wealth of information about real-world entities is not easily accessible to a user as she navigates the real world. Relevant information about a given entity is dispersed across multiple Web pages. For instance, a certain restaurant (e.g., IndoChine) may be mentioned in a review site, a blog post, a reservation site, or a deals site, etc. Currently, to discover all this information, it requires a human user to formulate the right keyword queries for search engines, and to navigate the search results, one web page at a time.
Our objective is to support more intuitive and seamless navigation of web information in the real world, one entity at a time. The key challenge is how to associate each entity with their relevant pages on the Web. More specifically, given a domain containing a set of entities and their known attribute values, the aim of this research is to find efficient ways to formulate query templates that leverage keyword-based search engines to discover the relevant pages. Some research issues that we pursue include query template mining (how to automatically identify suitable query templates for a given domain based on a probabilistic inference model), and graph sampling (how to achieve efficient inference without having to materialize the full web graph).
Organizing Web Information around Real-World Entities
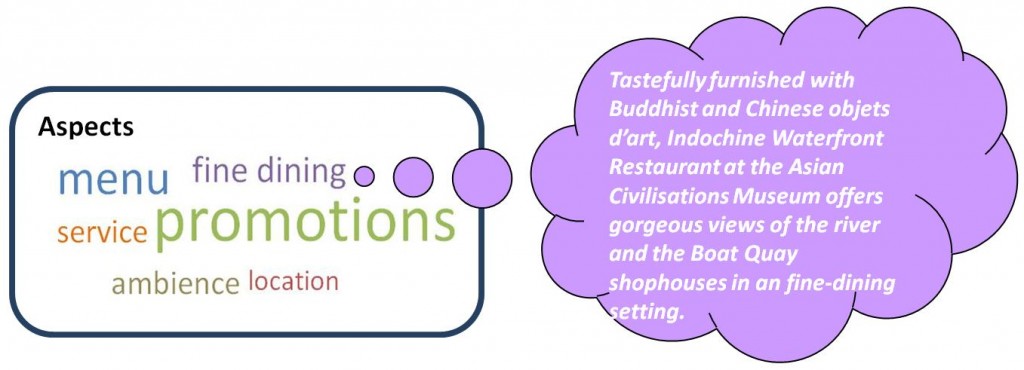 Given their abundance and diversity, web information for a given entity is not easily digested or consumed. Our goal is to organize unstructured text information around real-world entities, by distilling them into a set of aspects, and aligning segments within web pages to relevant aspects. For instance, in the case of restaurants, aspects may include “service”, “price”, etc. In turn, each aspect is associated with a set of relevant page segments, paragraphs, or sentences.
Given their abundance and diversity, web information for a given entity is not easily digested or consumed. Our goal is to organize unstructured text information around real-world entities, by distilling them into a set of aspects, and aligning segments within web pages to relevant aspects. For instance, in the case of restaurants, aspects may include “service”, “price”, etc. In turn, each aspect is associated with a set of relevant page segments, paragraphs, or sentences.
It is helpful if we can automatically discover such salient aspects from the massive text without asking human labeling from time to time, especially when the text content can dynamically change from site to site and from language to language. Therefore, we aim to solve the following problems with in this research: how to discover salient aspects consistently across entities of a given domain, how to rank aspects in terms of importance to each entity, and how to extract and align page segments to each aspect. Moreover, we approach this problem through statistical modeling of text information, without relying on costly supervision, so as to make it more scalable and domain-independent.
Comprehensive Integration of Relevant Information about Entities
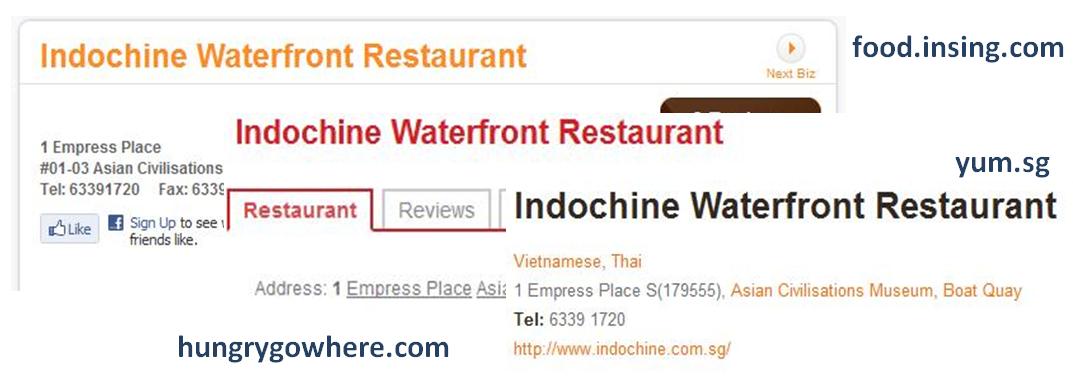 A significant amount of web information about entities are structured data. However, since the same entities may have been extracted from multiple Web pages, there can be many variances in the underlying data as well as presentation. Therefore, we may need to resolve the various occurrences of an entity and integrate their attribute values for a unified structure. Note that this task is not trivial. One one hand, the structured is usually not published cleanly (e.g. the formats of address can be different across different Web sites even for one specific restaurant). On the other hand, the data change over time (e.g. the address can be updated when a restaurant is moved to a new location). To solve the first problem, we need to extract and standardize the data before they can be used for further entity resolution. To solve the second problem, we need to continuously do data integration. In addition, we also want to exploit the contextual information from the Web page to help improve data integration. For example, we can use the hierarchy structures in the restaurant Web sites (e.g. yelp.com or insing.com); if two restaurants with same names have similar hierarchy structures (e.g. Cuisine -> Asian -> Korean) in different Web sites, then they are more likely to be the same restaurant.
A significant amount of web information about entities are structured data. However, since the same entities may have been extracted from multiple Web pages, there can be many variances in the underlying data as well as presentation. Therefore, we may need to resolve the various occurrences of an entity and integrate their attribute values for a unified structure. Note that this task is not trivial. One one hand, the structured is usually not published cleanly (e.g. the formats of address can be different across different Web sites even for one specific restaurant). On the other hand, the data change over time (e.g. the address can be updated when a restaurant is moved to a new location). To solve the first problem, we need to extract and standardize the data before they can be used for further entity resolution. To solve the second problem, we need to continuously do data integration. In addition, we also want to exploit the contextual information from the Web page to help improve data integration. For example, we can use the hierarchy structures in the restaurant Web sites (e.g. yelp.com or insing.com); if two restaurants with same names have similar hierarchy structures (e.g. Cuisine -> Asian -> Korean) in different Web sites, then they are more likely to be the same restaurant.
Integrating the Entity Information with Mobile Advertising
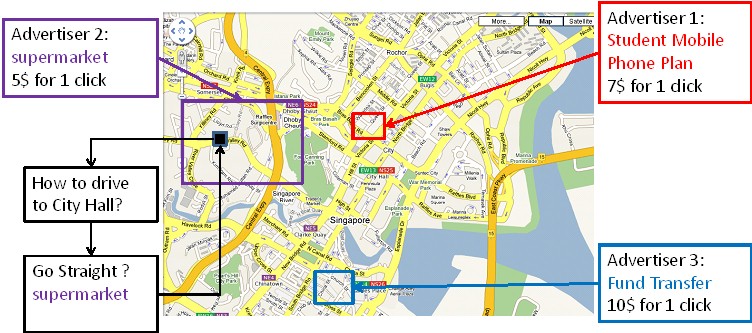 In addition to building the data store and enabling the search service, a holistic and end-to-end consideration of the application settings also requires the consideration of the use cases and what would be the optimal business models that can unlock the potential that access to such data brings.
In addition to building the data store and enabling the search service, a holistic and end-to-end consideration of the application settings also requires the consideration of the use cases and what would be the optimal business models that can unlock the potential that access to such data brings.